Research
– 10 min read
Reflect, retry, reward: Self-improving LLMs via reinforcement learning

Shelly Bensal | June 12, 2025

Large language models (LLMs) have advanced dramatically, but they still struggle with certain tasks, especially when high-quality training data is unavailable or difficult to produce. At WRITER, we recently explored a novel approach that significantly boosts LLM performance by teaching models how to effectively self-reflect on their errors using reinforcement learning. Our research, detailed in our latest paper, introduces a generalizable method that trains LLMs to not just correct mistakes on individual tasks, but also enhance their overall ability to self-improve across diverse challenges.
Introducing self-reflective LLM training
Traditionally, when a language model fails a task, the common solution is to retrain or fine-tune it on more relevant data. This can be problematic, however, if such data isn’t available. Instead, we propose a two-step approach where a model is prompted to first reflect on why it failed a task, and then given a second chance to retry with the benefit of this self-reflection.
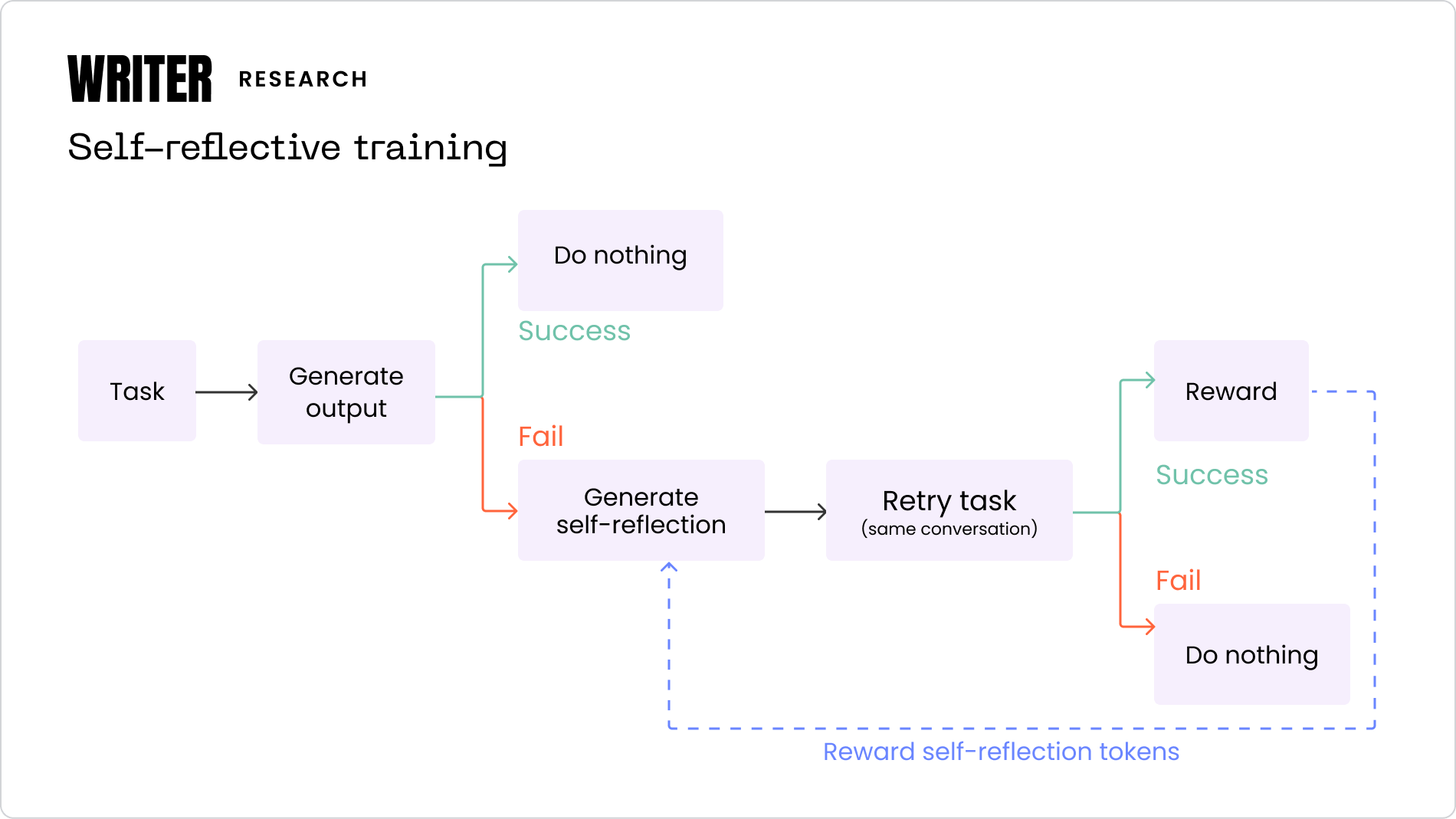
If the second attempt is successful, the reflection text itself is rewarded using Group Relative Policy Optimization (GRPO), selectively masking out all tokens except those generated during the reflection phase, reinforcing effective introspective behaviors rather than task-specific solutions.
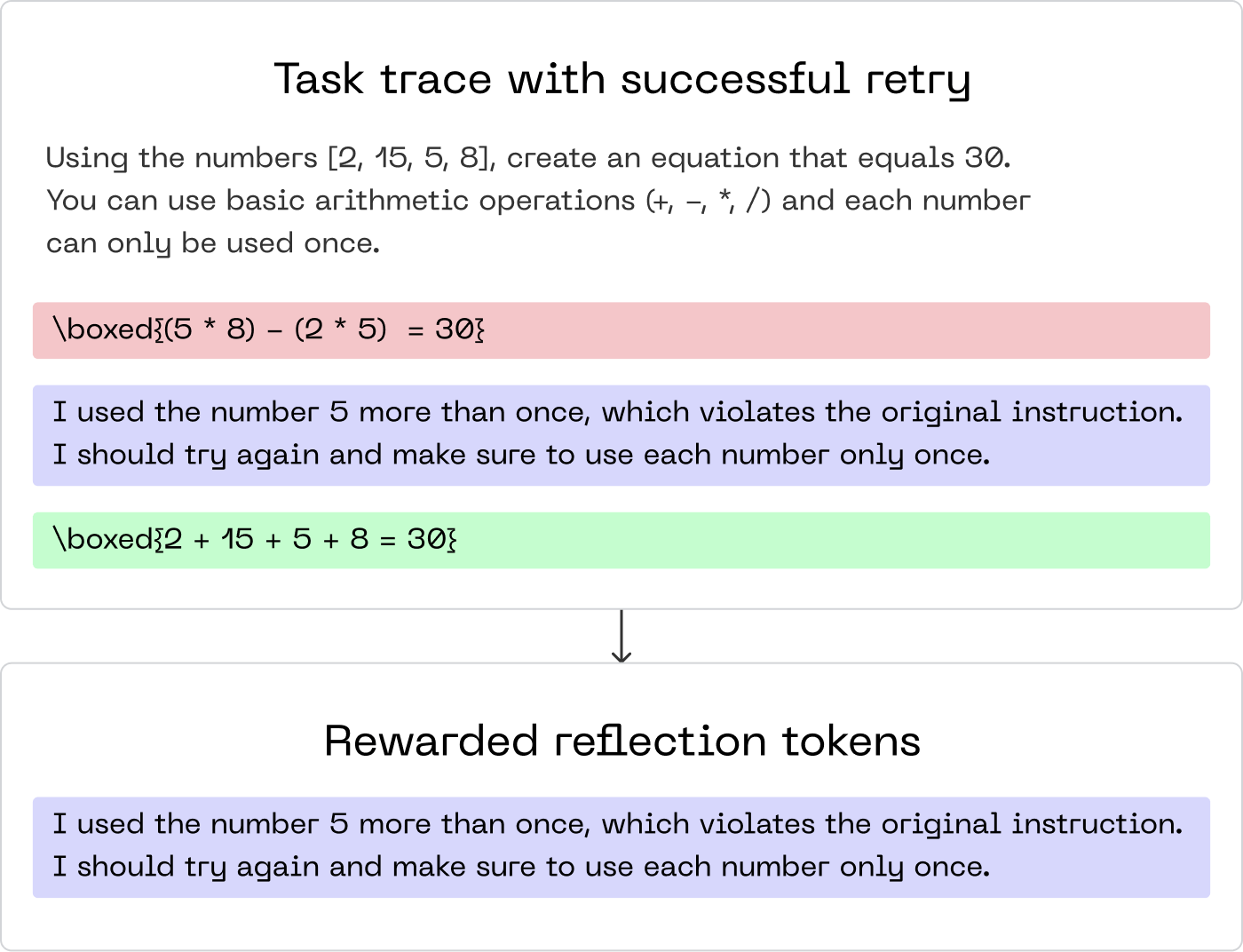
This innovative approach leverages only simple binary feedback (success or failure) and avoids reliance on additional labeled datasets or larger models for generating training data. This makes it particularly powerful for tasks like function calling or mathematical problem-solving, where success can be easily validated.
Main findings
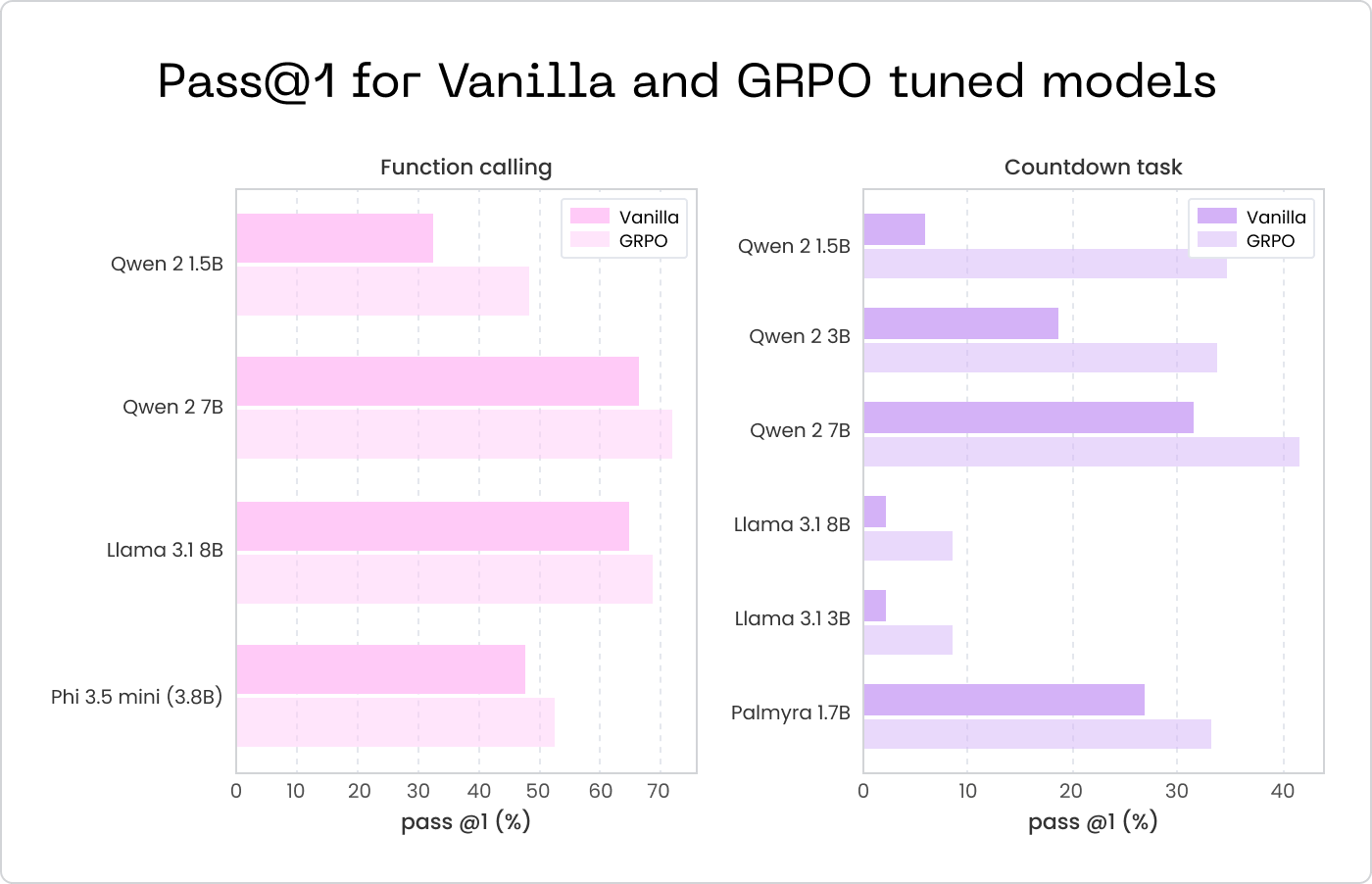
We tested our method extensively across two challenging datasets: APIGen for function calling and the Countdown dataset for mathematical equation writing. The results were impressive:
- Function calling tasks: Our method improved model accuracy by up to 18.1%, with smaller fine-tuned models (1.5B to 7B parameters) even surpassing performance of much larger, untrained models (70B+ parameters).
- Mathematical equation writing: Performance improvements reached as high as 34.7%, again demonstrating the ability of smaller models to achieve higher accuracy than significantly larger ones.
Notably, models fine-tuned with our self-reflection method exhibited minimal catastrophic forgetting. They maintained strong performance on general language understanding benchmarks (e.g., GSM8K, MMLU-Pro, HellaSwag, MATH), indicating that self-reflection acts as a meta-skill, broadly enhancing model reasoning without sacrificing previously learned capabilities.
Unlocking generalizable intelligence through self-reflection
Importantly, we also observed that after training, models generated significantly more concise and clearer self-reflections, likely contributing to their improved problem-solving capabilities. These optimized reflections suggest a pathway to better generalization across tasks, hinting that our method helps models internalize reasoning patterns rather than memorize specific solutions.
Our Self-Reflection framework thus opens exciting new possibilities for developing more reliable and versatile language models. We believe it represents a critical step toward building models that can autonomously enhance their capabilities through introspection and self-evolution.
For the full details, check out our paper.
More resources


Research
– 10 min read
Expecting the unexpected: A new benchmark for LLM resilience in finance — FailSafeQA
Writer Team