Thought leadership
– 21 min read
Vector database vs. graph database
A detailed comparison with Knowledge Graph implications

Ksenia Anske | October 7, 2024

Vector databases are great for fast searches but lack the context and relationships necessary for use in business settings. Graph databases excel at modeling complex data but struggle with large-scale processing. When considering a vector database versus a graph database, it’s important to weigh these strengths and limitations. Knowledge graphs combine the best of both worlds by storing and linking concepts, entities, and relationships using semantic descriptions. This makes them ideal for enterprise-level advanced search tasks because they preserve semantic relationships and encode structural information. When choosing a data storage technology for enterprise-scale search, consider data processing, query retrieval, and integration with LLMs. Knowledge graphs are often the best choice for these needs.

Nearly 54% of developers, according to 2023 Stack Overflow research, find that waiting on answers to their questions often causes interruptions and frequently disrupts their workflows.
The complement to this finding is also true: Nearly 47% of developers often find themselves answering questions they’ve answered before. The information is very often there, in other words, but it’s either locked inside the heads of teammates or buried so deep in other company resources that developers need someone’s help to find it.
If that sounds like a waste of time, imagine the same dynamic scaled across every department. No employee is spared: At some point, every person in every company has a question and has to wait for an answer.
This problem isn’t an unknown one. A variety of solutions have arisen over the years, including company intranets, wikis, and supposed paradigm shifts like digital transformation. All have posed advancements, but none have solved the seemingly simple but endlessly complex problem of getting questions answered.
This history is why RAG, or retrieval-augmented generation, is often seen as the holy grail of knowledge management.
By the time companies reach enterprise level, they’ve likely gone through numerous re-brands, restructurings, and pivots, with executives and board members coming and going and hundreds or thousands of employees onboarding and departing. In this context, answering even simple questions about the company can be challenging.
AI — via RAG — promises to be the first real solution. With RAG, employees ask natural language questions and task database tools to retrieve the information and use generative AI to formulate that information into a readable, relevant answer.
The initial results of RAG are powerful today and promising for what might come tomorrow, but those results also reveal significant limitations. Without a suitable database at the foundation, RAG can’t live up to its potential.
What is a vector database?
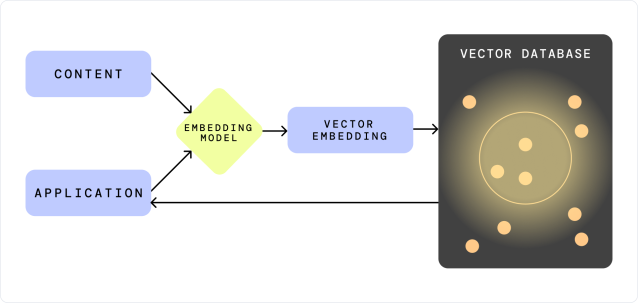
A vector database stores and maintains data in vector formatting. When data is prepared for storage, it’s split into chunks of characters ranging from 100 to 200. Then, with an embedding model, these chunks are converted into a vector embedding that can be stored in the vector database.
A vector database has many use cases, but a vector database, by definition, isn’t a complete foundation for RAG. Most vector databases don’t provide an embedding model, so companies typically need to find and integrate one to use a vector database as their foundation.
Vector databases also vary significantly depending on which algorithms they use. Vector databases use either K-Nearest Neighbors (KNN) or Approximate Nearest Neighbor (ANN) algorithms, and each has different effects on the final result of any search and retrieval features.
When users enter a query, the vector database converts the query into a vector embedding, and either a KNN or ANN algorithm determines which data points are closest to the query data point. As the name of each implies, both algorithms are similar, with ANN being more approximate but much faster.
Technical implementation example
Here’s a simple example of how a vector database might handle embeddings and similarity search using the FAISS library developed by Facebook AI Research:
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# Sample data chunks (simulated embeddings)
data_chunks = [
"Apple was founded as Apple Computer Company on April 1, 1976.",
"The company was incorporated by Steve Wozniak and Steve Jobs in 1977.",
"Its second computer, the Apple II, became a best seller.",
"Apple introduced the Lisa in 1983.",
"The Macintosh was introduced in 1984."
]
# Load the pre-trained Sentence Transformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Convert data chunks into embeddings
data_embeddings = model.encode(data_chunks)
# Build the FAISS index
dimension = data_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(data_embeddings)
# User query
query = "When did Apple introduce the first Macintosh?"
query_embedding = model.encode([query])
# Search for similar embeddings
k = 2 # Number of nearest neighbors
distances, indices = index.search(query_embedding, k)
# Retrieve and print the most similar chunks
for idx in indices[0]:
print(f"Retrieved chunk: {data_chunks[idx]}")Output:
Retrieved chunk: The Macintosh was introduced in 1984.
Retrieved chunk: Apple was founded as Apple Computer Company on April 1, 1976.As you can see, the vector database retrieves chunks based on vector similarity, which may not preserve the exact context needed to answer the question accurately.
The strengths and weaknesses of vector databases
Vector databases have a range of strengths and weaknesses, but the weaknesses tend to come to the forefront when companies try to use them to build RAG features. When considering a vector database versus a graph database, these weaknesses also tend to be more consequential when companies face them at an enterprise scale.
Strengths
The primary strength of vector databases is that companies can store different data types, including text and images.
Beyond sheer storage, vector databases also enable search functions that are much better than typical keyword searches. If users are looking for data that has semantic similarity, a vector database can often help them find those data points, even if there isn’t a literal keyword match.
Weaknesses
The primary weakness of vector databases comes from how vector databases process data. Especially in an enterprise context, where information retrieval needs to be granular and accurate, the crudeness of this data processing can show strain. When data is processed for vector storage, context is often lost. The relational context between data points is especially liable to get obscured.
The advantage vector databases have over keyword search — that vector databases can identify data-point similarity based on nearness (KNN and ANN) — becomes a weakness when compared to other databases. Beyond sheer numerical proximity, vector databases don’t preserve context that informs the relationships between different data points.
As Anthony Alcaraz, Chief AI Product Officer at fair hiring platform Fribl, writes, “Questions often have an indirect relationship to the actual answers they seek.” For example, consider a simple description of the origins of Apple:
Apple was founded as Apple Computer Company on April 1, 1976. The company was incorporated by Steve Wozniak and Steve Jobs in 1977. Its second computer, the Apple II, became a best seller as one of the first mass-produced microcomputers. Apple introduced the Lisa in 1983 and the Macintosh in 1984 as some of first computers to use a graphical user interface and mouse.
If this data is stored in a vector database, and a user queries, “When did Apple introduce the first Macintosh?”, correct data can turn into incorrect answers.
Given the crude chunking and the way KNN algorithms focus on mere proximity, the database might pull the closest chunks — “1983” and “Macintosh” instead of what the paragraph actually says. Given this wrong data, the LLM forms a confident but incorrect answer: “The first Macintosh was introduced in 1983.”
This loss of context is, again, especially consequential in enterprise contexts because, in these environments, data tends to be very sparse or very dense. In either case, vector searches tend to struggle or even fail to find and return relevant or complete answers. This weakness worsens in high-dimensional environments, where KNN algorithms fail to find meaningful patterns — a problem known as the “curse of dimensionality.”
Given the paucity of context, even an otherwise effective LLM will fail to formulate an accurate answer. Companies can run into the classic garbage-in and garbage-out problem: With little to no context and crude chunking, returned data points can be inaccurate or irrelevant to the query, setting LLMs up for failure. Generally, the more synthesis necessary, the worse vector databases tend to function.
Vector databases also tend to run into scalability, performance, and cost issues when used for RAG. Large datasets can make KNN algorithms inefficient, for example, and because KNN algorithms store datasets in memory, processing those often large datasets can become resource-intensive.
This intensiveness can increase quickly, too, because companies need to rerun and update the entire dataset when they enter new data. And as performance and scalability issues arise, so do costs.
Learn more: RAG vector database explained
What is a graph database?
Like a vector database, a graph database stores and maintains data, but its data storage structure is unique. Whereas vector databases often lose relational context, graph databases give primacy to relationships by using nodes and edges between data points to form graphs.
The unique nature of this relationship-first approach arose out of relational databases, an origin that makes graph databases worth considering for RAG. Relational databases store data in tables and organize similarly structured data closely together. Relational databases, however, don’t provide the ability to define relationships between tables.
As Kaleb Nyquist, the Database Manager at the Center for Tech & Civic Life, writes, “Ironically, graph databases are actually more relationship-oriented than relational databases.”
Graph databases tend to be best for modeling densely interconnected data. Because graph databases model data similarly to object-oriented languages, the resulting database contains direct pointers to related data points.
Technical implementation example
Here’s an example using Neo4j and its query language Cypher to store and query relationships:
// Create nodes
CREATE (apple:Company {name: 'Apple'})
CREATE (steveW:Person {name: 'Steve Wozniak'})
CREATE (steveJ:Person {name: 'Steve Jobs'})
// Create relationships
CREATE (steveW)-[:FOUNDED]->(apple)
CREATE (steveJ)-[:FOUNDED]->(apple)
// Query: Who founded Apple?
MATCH (founder)-[:FOUNDED]->(company {name: 'Apple'})
RETURN founder.nameOutput:
+---------------+
| founder.name |
+---------------+
| "Steve Wozniak"|
| "Steve Jobs" |
+---------------+This demonstrates how graph databases naturally model and query relationships between entities.
The strengths and weaknesses of graph databases
Graph databases were a hot topic in the database world only a few years ago, and in many cases, the emphasis on relationships makes them a useful tool. But in the years since, users of graph databases have also found weaknesses that make graph databases — without supplementation — a less-than-ideal choice for RAG purposes.
Strengths
Because they give primacy to relationships, graph databases tend to be most advantageous in contexts where the relationships between data points are essential for making meaning. Unlike relational databases, graph databases provide a native way of storing the relationships themselves, allowing developers to store relationships as memory pointers that lead from one entity to the next.
With the ability to define relationships directly, developers don’t need to worry about modeling those relationships in the database schema. Philipp Brunenberg, a data engineer, explains the benefits: “We do not need to know about foreign keys, and neither do we have to write logic about how to store them. We define a schema of entities and relationships, and the system will take care of it.”
Each relationship provides context between data points, but developers can also label the nodes and edges that form these relationships, allowing developers to assign weights and directionality to each relationship. As Brunenberg writes, “Direction provides meaning to the relationship; they could be no direction, one-way, or two-way.”
Graph databases also tend to be more easily understandable for non-technical users because the resulting models reflect the human mind and its visual dimensions. This visualization often makes them a top choice in contexts where knowledge needs to be retrieved, modeled, and displayed.
Weaknesses
Graph databases have a few weaknesses, especially regarding efficiency and efficacy.
Graph databases often run into efficiency problems when companies use them to process large volumes of data. In an enterprise context, where there can be a lot of sparse and dense data, graph database efficiency is especially likely to plummet.
Graph databases are also less effective when used to run queries that extend across databases. The larger these databases are, the less effective these queries become.
Developers are often drawn to graph databases because they’re known to be especially good at modeling relationships, but this advantage has limitations. Graph databases can, theoretically, model relationships well, but that doesn’t mean they can create better relationships. If data is poorly captured, the search and retrieval benefits won’t be fully realized.
What is a knowledge graph?
A knowledge graph is a data storage technique rather than a fundamentally different database. Knowledge graphs model how humans think — relationally and semantically — and go far beyond the numerical focus of vector databases and the relational focus of graph databases.
The knowledge graph technique collects and connects concepts, entities, relationships, and events using semantic descriptions of each. Each description contributes to an overall network (or graph), meaning every entity connects to the next via semantic metadata.
This technique for storing and mapping data mostly closely mimics how humans think in semantic contexts. This parallel makes it an ideal foundation for RAG-based search because RAG relies on natural language queries flowing through databases comprised primarily of semantic information.
The Writer Knowledge Graph, in particular, integrates RAG, offering users:
- Data connectors that link disparate data sources.
- A specialized LLM that processes data at enterprise scales to build meaningful semantic relationships amongst dense and sparse data points.
- A graph structure for data storage that can store both data points and data relationships while updating dynamically whenever new data is added.
- Retrieval-aware compression that can condense data and index metadata without accuracy loss.
Technical implementation example
- Semantic modeling: Uses ontologies and schemas (e.g., RDF, OWL) to define the types of entities and relationships.
- SPARQL queries: Employs SPARQL for powerful querying capabilities over the semantic data.
- Integration with LLMs: The knowledge graph interfaces with LLMs to enhance natural language understanding and generation.
For example:
from rdflib import Graph, Namespace, RDF, Literal
from rdflib.namespace import XSD
# Initialize graph
g = Graph()
# Define namespaces
EX = Namespace("http://example.org/")
g.bind('ex', EX)
# Add data to the graph
g.add((EX.Apple, RDF.type, EX.Company))
g.add((EX.Apple, EX.foundedOn, Literal("1976-04-01", datatype=XSD.date)))
g.add((EX.Steve_Wozniak, RDF.type, EX.Person))
g.add((EX.Steve_Jobs, RDF.type, EX.Person))
g.add((EX.Steve_Wozniak, EX.founded, EX.Apple))
g.add((EX.Steve_Jobs, EX.founded, EX.Apple))
# Querying the knowledge graph
query = """
PREFIX ex: <http://example.org/>
SELECT ?founderName ?companyName
WHERE {
?founder ex:founded ?company .
?founder ex:name ?founderName .
?company ex:name ?companyName .
}
"""
# Assuming names are added to the graph
g.add((EX.Steve_Wozniak, EX.name, Literal("Steve Wozniak")))
g.add((EX.Steve_Jobs, EX.name, Literal("Steve Jobs")))
g.add((EX.Apple, EX.name, Literal("Apple Inc.")))
# Execute the query
results = g.query(query)
for row in results:
print(f"{row.founderName} founded {row.companyName}")Output:
Steve Wozniak founded Apple Inc.
Steve Jobs founded Apple IncThis example showcases how knowledge graphs can store rich semantic relationships and facilitate complex queries.
The strengths and weaknesses of knowledge graphs
Knowledge graphs, built on graph databases, have many of the same advantages that graph databases have over vector databases. Knowledge graphs, however, also present advantages over graph databases in particular contexts — especially RAG.
Strengths
Knowledge graphs, like graph databases, store data points and their relationships in a graph database. Like graph and vector databases, knowledge graphs can store a wide variety of file formats, including video, audio, and text.
But in vector databases, queries are converted into a numerical format, often meaning context is lost. In knowledge graphs, queries don’t need to be reformatted, and the graph structure that uses these queries — because it preserves semantic relationships — allows for much more accurate retrieval than KNN or ANN algorithms can offer.
Search and retrieval – central to RAG — is especially effective in knowledge graphs. In enterprise contexts, the differentiator between effective and ineffective search is often the ability to synthesize data across multiple sources. Knowledge graphs encode topical, semantic, temporal, and entity relationships into their graph structure, making synthesis possible.
Relationships, however, aren’t always linear or one-way. With knowledge graphs, developers can encode hierarchies and other structural relationships. Given these structural relationships, knowledge graphs can map the connections between different points in different sources, even if they reference the same entities.
“In contrast,” Alcaraz writes, “standard vector search lacks any notion of these structural relationships. Passages are treated atomically without any surrounding context.”
Context loss is one of the most common weaknesses of other databases, especially when used for RAG. With knowledge graphs, contextual information is retained because it is encoded in the retrieved information.
Specialized LLMs, as used in the Writer Knowledge Graph, make this advantage even greater. By building richer semantic relationships, companies can preserve more context and maintain an intelligent definition of relationships across multiple dimensions.
For example, our Knowledge Graph uses a specialized LLM to create semantic relationships between data points, which improves accuracy and reduces the occurrence of hallucinations compared to traditional vector-based retrieval methods. When compared with other RAG approaches on the basis of accuracy, the Writer Knowledge Graph achieved an impressive 86.31% on the RobustQA benchmark, significantly outperforming the competition, which scored between 75.89% and 32.74%. The evaluation included vector retrieval RAG solutions such as Azure Cognitive Search Retriever with GPT-4, Pinecone’s Canopy framework, and various LangChain configurations.
Weaknesses
Due to their emphasis on semantic information, knowledge graphs tend to have a lot of data to condense, often resulting in the need for significant computational power to support them. Operations running across knowledge graphs can sometimes be expensive, and that costliness can make them difficult to scale.
And, similar to the weaknesses inherent to graph databases, knowledge graphs can’t take on the work of capturing and cleaning data well. Similarly, an effective knowledge graph will be hampered by an LLM that can’t formulate readable answers without hallucinations.
Technical considerations
You could build and optimize a knowledge graph yourself, but this would require:
- Expertise in semantic technologies: Proficiency in RDF, OWL, and SPARQL.
- Efficient data modeling: Ability to create ontologies that accurately represent your domain.
- Infrastructure management: Setting up and maintaining scalable graph databases, which can handle distributed storage and processing.
- Performance tuning: Implementing indexing strategies, caching mechanisms, and query optimizations to handle large-scale data efficiently.
- LLM fine-tuning: Training or fine-tuning LLMs to work effectively with your knowledge graph, reducing hallucinations and improving response quality.
Alternatively, using a solution like the Writer Knowledge Graph can provide:
- Out-of-the-box integration: Pre-built connectors and tools for data ingestion and modeling.
- Optimized performance: Infrastructure designed to handle enterprise-scale data with efficient querying and retrieval.
- Seamless LLM integration: Specialized LLMs already tuned to work with the knowledge graph, improving accuracy.
- Cost efficiency: Reducing the need for in-house development and maintenance resources.
How to choose the right data storage to support RAG for enterprise
RAG is a particular enough use case that choosing a general-purpose data storage technology, whether well-reputed or not, will likely not suit RAG. If you’re exposing RAG to users, the efficiency of the search and the accuracy of the retrieved information must be extremely high for those users to trust it.
This article has covered a lot of different technologies and their nuances, so first, take a step back. Knowledge retrieval across any database requires three basic tasks. One way to compare these databases, then, is to evaluate which database technology will support each task.
- First, the database has to process the data. How will the database split volumes of data into smaller chunks to be stored in a data structure?
- Second, the database has to offer the ability to query for information and retrieve it. How will the database use a query to retrieve relevant pieces of data that can answer that query?
- Third, the database has to formulate data to allow an LLM to generate an answer. How well will the database send that relevant data to an LLM for answer generation?
Knowledge graphs stand out across these questions. Knowledge graphs are especially useful for companies using RAG, but the differences widen when companies use RAG at an enterprise scale.
In a Knowledge Graph and LLM Accuracy Benchmark Report, researchers found that the accuracy of answers increased from 16%, based on GPT-4 and SQL databases, to 54% when using a knowledge graph representation of the same SQL database.
This accuracy difference isn’t just important for RAG; it’s often make or break. When users have questions, they, by definition, lack answers, so when a poorly implemented RAG returns inaccurate answers or hallucinations, the confusion can be consequential. With the stakes this high, it doesn’t take many mistakes for users to consider an otherwise accurate RAG untrustworthy.
RAG success depends on your foundational choices
It’s best to ship fast and iterate in many software development contexts.
Startups, for example, tend to benefit from building products with the most accessible technologies, shipping them to potential users, and figuring out which direction they’ll build in based on the results. Ship the product; get feedback on the product and the technologies supporting it; iterate; and ship again.
Enterprises, however, particularly those building features that rely on high trust amongst users, can’t afford to rush in and iterate later. RAG depends so much on the earliest, most fundamental technical decisions that intensive research has to be done upfront. Iteration and feedback will still be necessary, but if enterprises build the wrong foundation, the iteration will eventually involve migration or rebuilding instead of incremental improvement.
The research challenge matches the complexity of the task. An enterprise contains a lot of information, but it’s not laid out like a book; an enterprise more closely resembles layers of sedimentary rock comprising many materials built up over many years.
The complexity is emergent, and no amount of pre-work can make an enterprise’s information simple to parse, map, and retrieve. Instead, if companies want to build enterprise-ready RAG, they need to face the complexity with a tool built — from the ground up — to handle that complexity.
Knowledge Graph, the graph-based retrieval-augmented generation (RAG) from WRITER, achieves higher accuracy than traditional RAG approaches that use vector retrieval. Learn more and request a demo.