Product updates
– 9 min read
WRITER’s Palmyra X5 on Amazon Bedrock: Unlock long context AI for enterprise

Ashley Weaver | September 5, 2025

Following Palmyra X5’s release on Amazon Bedrock in April, developers have been using Palmyra X5’s deep thinking and tool-calling capabilities for greater accuracy and reliability. This integration provides developers with a secure, managed API to build powerful, enterprise-ready AI agents that can reason over massive datasets without managing any infrastructure. In this post, we’ll walk you through how this comes to life with a Text-to-SQL agent that turns natural language questions into precise SQL queries, interacting with AWS services like Glue and Athena to deliver real-time insights from a financial database.

In April 2025, WRITER unveiled Palmyra X5 on Amazon Bedrock, a state-of-the-art adaptive reasoning foundation model featuring built-in tool calling, a 1 million token context window, and cost efficiency designed for scale.
Following that, developers have been using Palmyra X5’s deep thinking capabilities to achieve stronger and more predictable tool calling, enabling more complex enterprise use cases on Bedrock.
What makes this release so powerful? By running on Amazon Bedrock, Palmyra X5 becomes accessible through a secure, fully managed API that eliminates infrastructure overhead. Developers get the best of both worlds with Palmyra X5’s enterprise grade deep reasoning and massive context combined with Bedrock’s scalability, compliance, and orchestration tools — it’s now easier than ever to bring long context reasoning into the enterprise.
Key features
WRITER’s foundation models on Amazon Bedrock give engineering teams the tools they need to build enterprise ready AI agents, powered by a few key capabilities:
- Unified API access: access Palmyra X5 through Bedrock’s fully managed API, making it easy to integrate reasoning and long context capabilities into applications without standing up or managing infrastructure.
- Enterprise grade scalability: Run Palmyra X5 at scale on AWS infrastructure, ensuring that its 1 million token context window and tool calling workflows can handle enterprise workloads reliably and cost-effectively.
- Customizable workflows: use Bedrock’s data automation, external data sources, prompt management, and more to adapt Palmyra X5 to your organization’s enterprise data.
- Custom orchestration: combine Palmyra X5’s dynamic reasoning and tool calling with Bedrock’s orchestration capabilities to build multi-step pipelines and agentic applications.
By combining Palmyra X5 with Amazon Bedrock, developers can build and scale AI agents that reason over massive enterprise data sets, all while maintaining the security, scalability, and performance required for enterprise production environments.
Text-to-SQL agent: Palmyra X5 on Amazon Bedrock in action
Let’s walk through an example text-to-SQL agent that uses WRITER’s Palmyra X5 on Amazon Bedrock. To follow along, you can find the full example in our GitHub repository.
This Amazon Bedrock agent uses Palmyra X5 to turn natural language questions into SQL queries that it executes against an enterprise financial dataset. With tool calling, the agent retrieves schema details from the AWS Glue Data Catalog and runs queries in Amazon Athena against data stored in Amazon S3. AWS Lambda acts as the glue that connects these services together, orchestrating calls and returning results back through Bedrock so Palmyra X5 can generate accurate SQL queries.
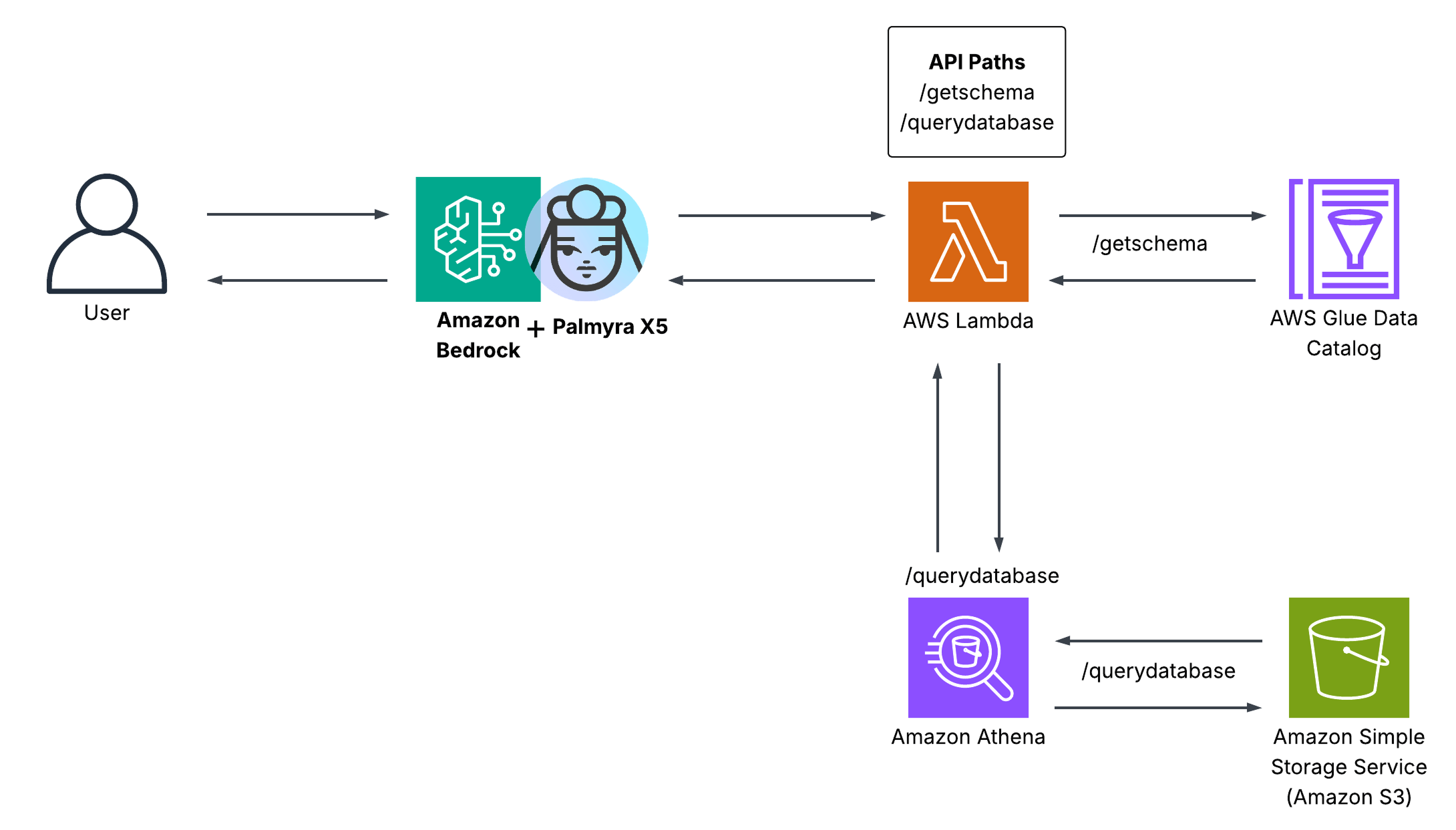
With the architecture in mind, let’s dive into the code that makes this possible.
main.py
This is the entry point for interacting with Palmyra X5 on Amazon Bedrock. It captures user queries from the command line, sends it to the Bedrock agent for processing, and streams the agent’s responses back to the console.
# main.py - Core interaction loop
def invoke_text_to_sql(query, agent_id, agent_alias_id):
agent_response = bedrock_agent_runtime_client.invoke_agent(
inputText=query,
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=str(uuid.uuid4()),
enableTrace=True,
)
for event in agent_response.get("completion"):
if formatted_response := format_agent_response(event):
print(formatted_response)lambda_function.py
This Lambda function acts as the bridge between Palmyra X5, running on Amazon Bedrock, and the AWS data services the agent needs to query. It exposes two key tools that the agent can call through tool calls:
/getschema: uses AWS Glue to fetch table names, columns, and data types from thefinancialdatadatabase, giving Palmyra X5 the schema it needs to generate accurate SQL/querydatabase: runs the generated SQL against the dataset stored in Amazon S3 via Amazon Athena, waits for completion, and returns the results
Together, these functions turn /getschema and /querydatabase into callable tools for Palmyra X5.
# utils/lambda_function.py - Get Database Schema
def get_schema():
try:
print("'/getschema' has called.")
glue_client = boto3.client("glue")
database_name = "financialdata"
table_schema_list = []
response = glue_client.get_tables(DatabaseName=database_name)
table_names = [table.get("Name") for table in response.get("TableList", [])]
for table_name in table_names:
response = glue_client.get_table(
DatabaseName=database_name, Name=table_name
)
columns = (
response.get("Table", {})
.get("StorageDescriptor", {})
.get("Columns", [])
)
schema = {column.get("Name"): column.get("Type") for column in columns}
table_schema_list.append({f"Table: {table_name}": f"Schema: {schema}"})
return table_schema_list
except Exception as e:
error_message = f"Error in 'get_schema' handler occurred: {str(e)}"
print(error_message)
return error_message
# utils/lambda_function.py - Execute SQL Query
def execute_athena_query(query):
try:
print("'/querydatabase' has called.")
athena_client = boto3.client("athena")
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={"Database": "financialdata"},
ResultConfiguration={"OutputLocation": outputLocation},
)
query_execution_id = response.get("QueryExecutionId")
print(f"Query Execution ID: {query_execution_id}")
response_wait = athena_client.get_query_execution(
QueryExecutionId=query_execution_id
)
while response_wait.get("QueryExecution", {}).get("Status", {}).get(
"State", ""
) in ["QUEUED", "RUNNING"]:
print("Query is still running.")
response_wait = athena_client.get_query_execution(
QueryExecutionId=query_execution_id
)
if (
response_wait.get("QueryExecution", {}).get("Status", {}).get("State", "")
== "SUCCEEDED"
):
print("Query succeeded!")
query_results = athena_client.get_query_results(
QueryExecutionId=query_execution_id
)
extracted_output = extract_result_data(query_results)
print(extracted_output)
return extracted_output
else:
print(f"Query {query_execution_id} haven't reached 'SUCCEEDED' status.")
return None
except Exception as e:
error_message = f"Error in 'execute_athena_query' handler occurred: {str(e)}\nExecution query: {query}"
print(error_message)
return error_messageResults
Let’s see this in action with a simple query. When a user asks, “What customer has the highest transaction amount?”, main.py captures the input and passes it to Palmyra X5. The agent uses /getschema to understand the table structure and /querydatabase to run the generated SQL against Athena. Finally, the results are formatted and returned, showing how Palmyra X5 and Bedrock work together with tool calling to turn natural language questions into precise, real-time, enterprise insights.
🧠 Text to SQL Agent 🧠
Options:
'exit' - Exit the program
> what customer has the highest transaction amount?
Calling LLM...
Trying to call /getschema...
Trying to call /querydatabase...
Final response were generated!
The customer with the highest transaction amount is Connie Henderson, with a transaction amount of $499.86.
SELECT c.first_name, c.last_name, t.amount
FROM customer_data c
JOIN transaction_data t ON c.customer_id = t.customer_id
ORDER BY t.amount DESC
LIMIT 1;
Query Results:
- First Name: Connie
- Last Name: Henderson
- Highest Transaction Amount: $499.86
> exit
Goodbye! 👋For a deeper dive into building with WRITER’s foundation models on Amazon Bedrock and integrating it into your enterprise workflows, check out our guide on how to invoke Palmyra models on Amazon Bedrock.
Get started today
The Palmyra X5 Amazon Bedrock integration makes it easy to build enterprise-ready AI agents that combine X5’s long-context reasoning and tool-calling with Bedrock’s orchestration, scalability, and security.
Ready to get started? Check out our full integration guide and GitHub repository for additional resources and examples. Reach out to us on LinkedIn to let us know what you build!
More resources


Product updates
– 8 min read
Enterprise-grade AI meets multi-agent orchestration: WRITER integrates with Strands Agents SDK
Ashley Weaver