Product updates
– 6 min read
Introducing Palmyra Med and Palmyra Fin
New healthcare and finance models achieve top medical benchmarks and pass the CFA Level III exam

Sam Julien | July 31, 2024

This blog post introduces Palmyra Med and Palmyra Fin, specialized models for healthcare and finance. They’ve received top benchmark results, with Palmyra Fin passing the CFA Level III exam. The post covers model performance, applications, and accessibility via the WRITER platform.

Palmyra Med and Palmyra Fin are live! We’re excited to welcome both models to our family of WRITER-built LLMs. These models are trained for precision in medical and financial generative AI applications, powering AI workflows in two industries that are known for their strict regulation and compliance standards. They outperform other models like GPT-4, Med-PaLM-2, and Claude 3.5 Sonnet. Palmyra Fin even got 73% on the CFA Level II exam, making it the first model to ever pass.
You can find both Palmyra Med and Palmyra Fin on our models page under an open-model license. You can also access them via our API, No-code tools, and the WRITER Framework.
Passing the CFA level III exam with Palmyra Fin
There are some unique challenges to adopting generative AI in the financial sector. For example, financial statements are often lengthy, and use complex terminology and market analysis. By combining a well-curated set of financial training data with custom fine-tuning instruction data, we’ve trained a highly accurate financial LLM that can power use cases like:
- Financial trend analysis and forecasting: Examining market dynamics and developing financial performance forecasts.
- Investment analysis: Producing detailed evaluations of companies, industries, or economic markers.
- Risk evaluation: Assessing the potential hazards linked to different financial tools or approaches.
- Asset allocation strategy: Recommending investment mixes tailored to individual risk preferences and financial objectives.
Domain-specific models like Palmyra Fin bring the skills and knowledge needed to support these complex financial use cases. This was evident in our long-fin-eval benchmark test, an internally created benchmark designed to test real-world financial use cases and long-form financial document analysis. Palmyra Fin outperformed popular models like Claude 3.5 Sonnet, GPT-4o, and Mixtral-8x7b — demonstrating its ability to tackle complex financial tasks and power AI apps and fetures.
In an ad hoc experiment, we also tasked Palmyra Fin with passing the CFA Level III exam — one of the most difficult tests in investment management. The model passed with flying colors on a 0-shot attempt, scoring 73%. By comparison, the average score for human test takers over the past 11 years has been about 60%.
We achieved these results using a sample test and some basic prompting techniques.
We used the following prompt:
Take a moment to calm your mind and focus. You are preparing for the CFA® Level III exam, which demands precision and deep understanding. Carefully read the scenario provided and the subsequent question. Your task is to analyze the scenario and select the most appropriate answer from the options given.
Scenario: [File input]
Question: [Question]
Please provide:
Your Answer: Choose A, B, or C.
Explanation: a brief reasoning of why you chose that answer
Each scenario was submitted as a PDF file, and questions were asked one at a time. We performed this test using Writer AI Studio to make it easier to upload files and manage inputs.
While we don’t think you should replace your financial advisor anytime soon, Palmyra Fin’s performance is an exciting indicator of the kind of support financial experts can receive from innovative AI applications.
Improving domain-specific accuracy for medical AI applications
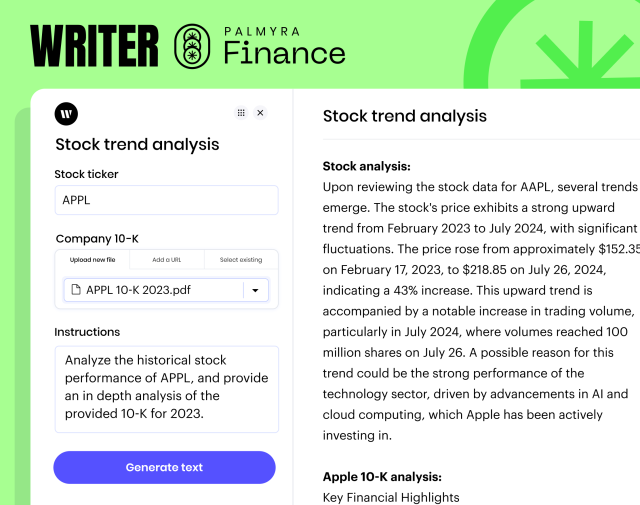
In our testing, Palmyra Med averaged 85.9% on all medical benchmarks, beating the runner-up, Med-PaLM-2, by nearly two percentage points. Med-PaLM-2 only achieved these results after a 5-shot attempt, compared to Palmyra’s zero-shot performance.
The model has a range of skills and knowledge that can help improve patient outcomes and research, including:
- Clinical knowledge and anatomy: With scores of 90.9% on the MMLU Clinical Knowledge and 83.7% on the MMLU Anatomy, Palmyra-Med-70b demonstrates a robust understanding of clinical procedures and human anatomy. This makes it exceptionally useful for supporting diagnostic accuracy and treatment planning in medical settings.
- Genetics and college medicine: Scoring 94.0% in Medical Genetics and 84.4% in College Medicine, the model excels at interpreting genetic data and applying complex medical knowledge, which is critical in genetic counseling and medical education.
- Biomedical research: With a score of 80% on PubMedQA, Palmyra-Med-70b proves its capability to effectively extract and analyze information from the biomedical literature, supporting research and evidence-based medical practice.
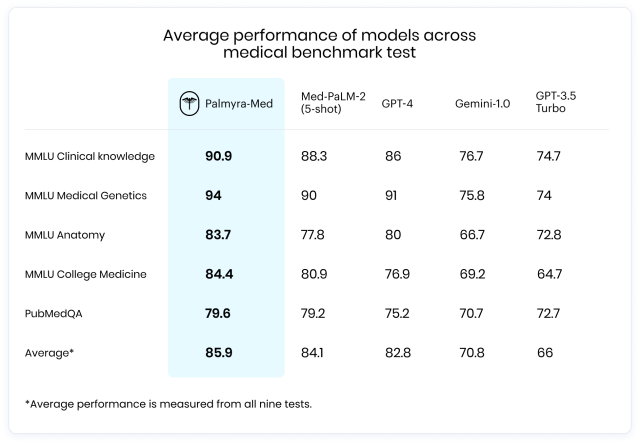
Palmyra-Med-70b delivers superior medical benchmark performance at a price of $10 per 1M output tokens — substantially less expensive than larger frontier models like GPT-4, which costs $60 for the same amount of output. This makes Palmyra-Med-70b an attractive option for medical professionals and institutions and illustrates a key advantage of domain-specific models.
The WRITER full-stack generative AI platform is used by world’s leading Fortune 50 healthcare companies, as well as healthcare innovators like Vizient, CirrusMD, and Medisolv, to help improve patient outcomes with powerful generative AI applications that are infused with deep medical knowledge.
Getting started with Palmyra LLMs
Palmyra Med and Palmyra Fin are available on NVIDIA NIM, Hugging Face, and on our full-stack generative AI platform — which includes graph-based RAG, AI guardrails, and our family of WRITER-built LLMs. Our platform has two primary ways to build: with our APIs or with the WRITER Framework.
The WRITER Framework is an open-source framework for building feature-rich AI apps with a visual editor and an extensible Python backend. It’s deeply integrated with our full-stack generative AI platform. With just a few lines of code, you can access our APIs directly within your AI apps — no need to build a stack. Here’s an example:
import writer as wf
import writer.ai
def generate_analysis(state):
answer = writer.ai.complete("Can you explain how central banks printing more money (quantitative easing) affects the stock market and how investors might react to it?", config={"model": "palmyra-fin-32k", "temperature": 0.7, "max_tokens": 8192})
print(answer)We also have robust SDKs for our APIs. Here’s that same prompt, but using our Python SDK.
import os
from writerai import Writer
client = Writer(
# This is the default and can be omitted
api_key=os.environ.get("WRITER_API_KEY"),
)
stream = client.completions.create(
model="palmyra-fin-32k",
prompt="Can you explain how central banks printing more money (quantitative easing) affects the stock market and how investors might react to it?",
stream=True,
)
for completion in stream:
print(completion.value)We encourage you to give both a try. New AI Studio accounts get $10 in free API credits to test out the models and start building. We can’t wait to see what you create!
Domain-specific LLMs will be at the forefront of AI innovation, changing the way industries build specialized AI applications. We’re excited to contribute to this movement by creating models like Palmyra Med and Palmyra Fin — models with deep, domain-specific expertise that are uniquely suited for enterprise use cases.
More resources


Research
– 10 min read
Palmyra Med: instruction-based fine-tuning of LLMs enhancing medical domain performance
Writer Team
{kind=link}