Engineering
– 9 min read
When too many tools become too much context
Learn how RAG-MCP improves tool selection and reduces context rot in MCP-based systems.

Ashley Weaver | November 25, 2025

In the world of MCP, an LLM can theoretically access an infinite number of tools. Of course, that’s an exaggeration, but as the number of callable tools grows, a new challenge emerges — how does the model know which one to call?
When every function, API, or integration gets stuffed into a single prompt, models run into a problem known as context rot — when flooding a model’s context window with too much information can actually degrade reasoning. Functions start to blur together, and even advanced models struggle to pick the right one or reason effectively about when to use it.
My colleague Dennis Thompson wrote about these same challenges in his recent post, “Avoiding context rot and improving tool accuracy for AI agents using MCP”. He captured the core issue of context rot, but it’s also part of a bigger picture — how we manage and structure context itself.
In his post, Dennis outlined three key hurdles in building WRITER’s enterprise-grade MCP Gateway, a gateway that sits between WRITER’s agents and external MCP servers system:
- How to provide an agent with hundreds of tools without the manual creation of each description.
- How to ensure the LLM finds and uses the correct tool.
- How to make sure these tools won’t bloat the context window.
WRITER’s MCP Gateway architecture addresses this by acting as a control layer that automatically ingests APIs via OpenAPI or Postman, rewrites tool descriptions using Palmyra X5 for LLM clarity, and applies vector-based retrieval to rank and distill hundreds of granular endpoints into a small set of “meta-tools.”
As an agent’s toolbox grows, so does the complexity of managing it. Our MCP Gateway architecture work addresses the challenge of governing and scaling tools across the enterprise. Let’s explore the context engineering side — how retrieval-based methods like RAG-MCP can help models select, compress, and isolate the most relevant tools in context.
Write, select, compress, isolate
At its core, context engineering is systems discipline — how we structure, retrieve, and manage information so that LLMs can reason effectively. It spans several overlapping disciplines — RAG, memory, state, history, prompt engineering, and structured outputs — all working together to decide what context a model should see, ignore, or reuse across state, store, and runtime context.
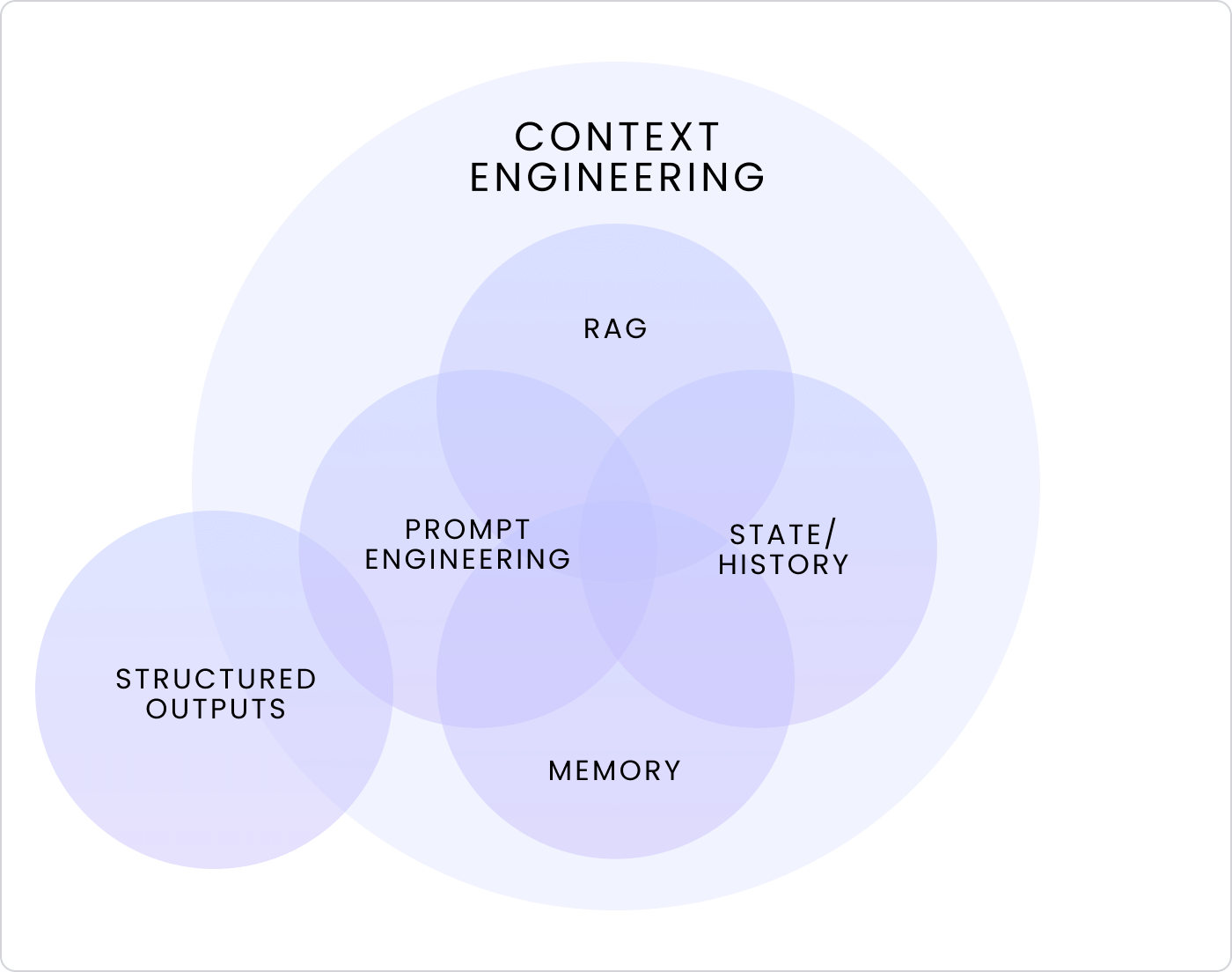
Where prompt engineering focused on crafting better inputs, context engineering is about designing better systems for giving a model the right context at the right time. In practice, this typically comes down to four key moves — write, select, compress, and isolate.
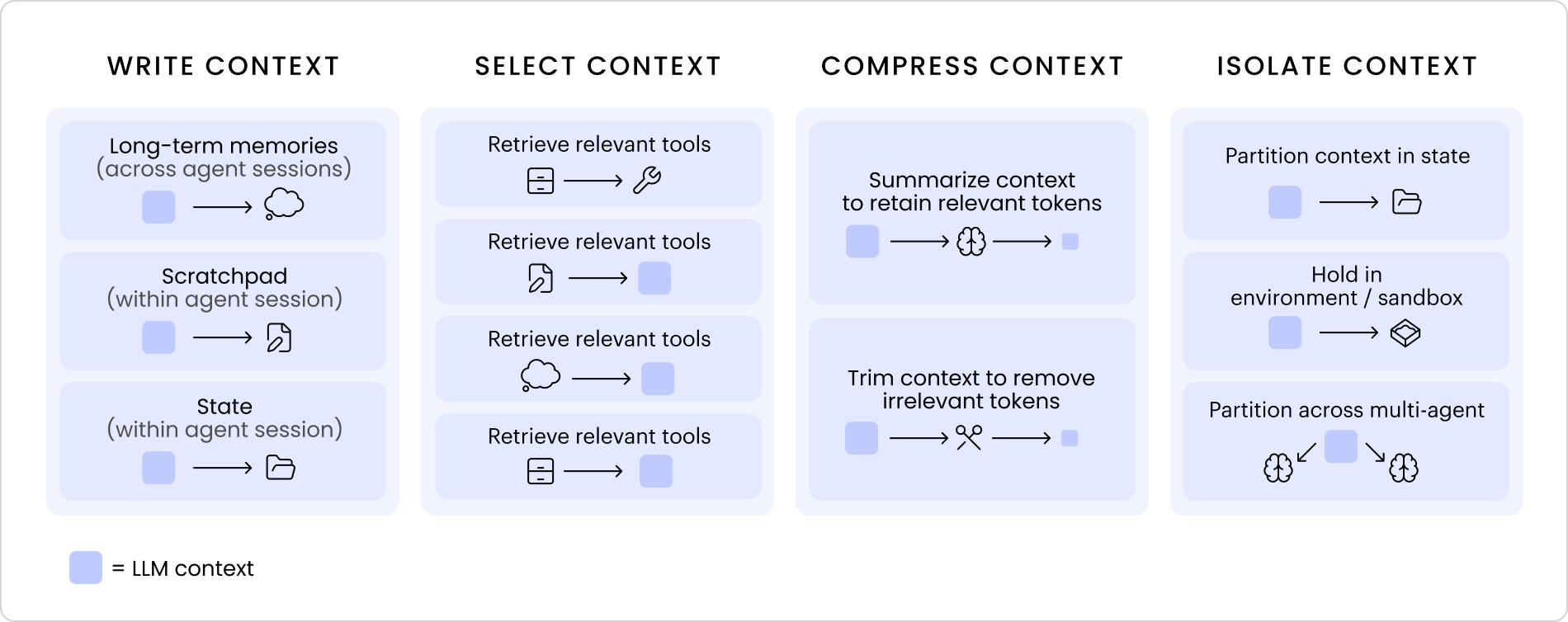
Together, they form the backbone of context engineering, each approach key to tackling context rot:
- Write: save relevant context outside the window
- Select: retrieve what’s most relevant
- Compress: keep only what’s needed
- Isolate: partition context for focus
These steps provide a mental model for how complex agentic systems can stay reliable as they scale.
RAG-MCP
One approach to context engineering for tool calling is through retrieval frameworks like RAG-MCP, which offload tool discovery by using semantic retrieval to identify the most relevant tools for a given query from an external index before passing it to an LLM. Instead of loading every possible tool into a model’s context, RAG-MCP introduces a retrieval layer that selects, compresses, and isolates only what’s relevant in the moment. The goal isn’t to give models more tools, but to help them retrieve and reason with the right ones at the right time, rethinking how we give LLMs the right context to perform their tasks effectively.
We can break RAG-MCP down into three main stages of retrieval:
- Embed and search: represent both the query and all tool descriptions in a shared vector space
- Rank and select: score tools by semantic distance and return the top matches
- Inject and reason: feed those selected tools into the LLM’s context so it can reason and decide which to call
To visualize this process, I created a lightweight diagram showing RAG-MCP at a base level.
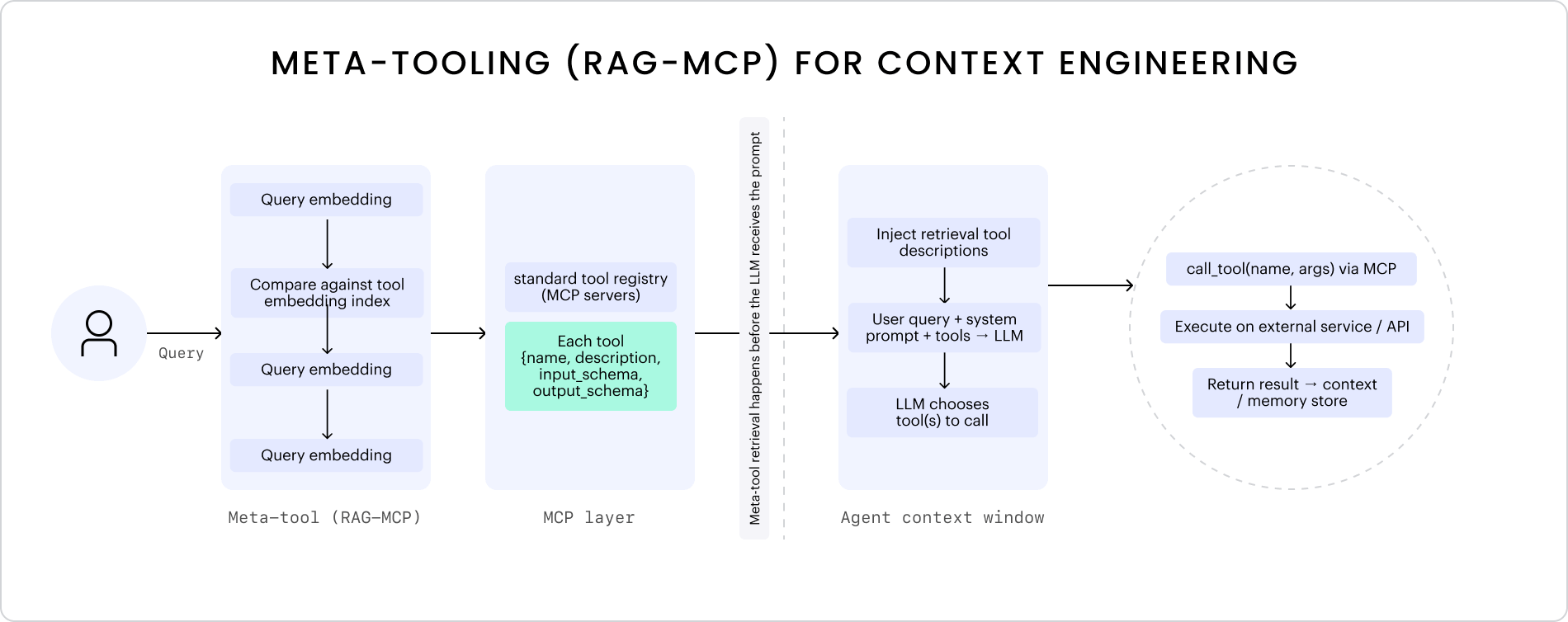
In the RAG-MCP paper, this approach more than triples tool-selection accuracy and reduce prompt tokens by over 50%, making models more efficient and reliable when reasoning across large toolsets. It’s a strong example of how context engineering helps avoid prompt bloat by separating retrieval from reasoning.
A lightweight RAG-MCP prototype
To explore these ideas in practice, let’s look at a lightweight RAG-MCP prototype using sentence-transformers for the retrieval layer. The goal is to embed each MCP tool in a shared vector space, retrieve the most semantically relevant ones for a given query, and inject only those tools into the model’s context before reasoning.
"""
RAG-MCP: Retrieval-Augmented Generation with MCP
Lightweight prototype demonstrating the core retrieval and injection flow.
"""
import asyncio
from typing import List, Dict, Any
import httpx
import numpy as np
from sentence_transformers import SentenceTransformer, util
# Configuration
DEFAULT_MCP_ENDPOINT = "<your_mcp_server_endpoint>" # e.g. http://localhost:3000
class RAGMCP:
"""Core RAG-MCP steps:
1. Index tools with embeddings
2. Rank tools by semantic similarity
3. Inject relevant tools into context
"""
def __init__(self, mcp_endpoint: str, embedding_model: str = "all-MiniLM-L6-v2"):
self.mcp_endpoint = mcp_endpoint
self.embedding_model = SentenceTransformer(embedding_model)
self.tool_embeddings: List[np.ndarray] = []
self.tools: List[Dict[str, Any]] = []
async def initialize_tool_registry(self):
"""Step 1: Fetch MCP tools and index them with embeddings"""
async with httpx.AsyncClient() as client:
response = await client.post(
self.mcp_endpoint,
json={"jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}},
headers={"Content-Type": "application/json"},
)
self.tools = response.json()["result"]["tools"]
tool_texts = [f"{t['name']}: {t['description']}" for t in self.tools]
self.tool_embeddings = self.embedding_model.encode(tool_texts)
def retrieve_tools(self, query: str, top_k: int = 3) -> List[Dict[str, Any]]:
"""Step 2: Rank tools by semantic similarity"""
query_emb = self.embedding_model.encode([query])
similarities = util.cos_sim(query_emb, self.tool_embeddings)[0]
top_indices = similarities.argsort(descending=True)[:top_k]
return [
{**self.tools[i], "similarity_score": similarities[i].item()}
for i in top_indices
]
def build_prompt_with_tools(self, tools: List[Dict[str, Any]], query: str) -> str:
"""Step 3: Inject relevant tools into the model’s context"""
tool_descriptions = [
f"- {t['name']}: {t['description']} (similarity: {t['similarity_score']:.3f})"
for t in tools
]
return f"""
Available tools:
{chr(10).join(tool_descriptions)}
Query: {query}
Please respond with either:
1. A direct answer if no tool is needed
2. A tool call in the format:
{{"tool_call": {{"name": "tool_name", "arguments": {{...}}}}}}
"""
# Example usage
async def main():
rag_mcp = RAGMCP(DEFAULT_MCP_ENDPOINT)
await rag_mcp.initialize_tool_registry()
query = "Add a file to the marketing Knowledge Graph"
tools = rag_mcp.retrieve_tools(query)
print(rag_mcp.build_prompt_with_tools(tools, query))
if __name__ == "__main__":
asyncio.run(main())You can find the code example here, but at a high level, this setup:
- Embeds each MCP tool’s name and description into a shared vector space
- Retrieves and ranks the most semantically relevant tools for a given query
- Injects only those tools into the model’s context before reasoning
While this example focuses on the retrieval and context-injection layer, the next step would be to send this filtered context to your model of choice, like WRITER’s Palmyra X5, to reason and decide which tool to call.
My takeaways
Context engineering really comes down to tradeoffs. Every decision forces you to choose what to include versus compress, what to retrieve automatically versus ignore, and when to reason locally versus defer to external tools.
The more we can separate what to remember (retrieval and context management) from how to think (reasoning and decision-making), the more effectively agentic systems can reason — reducing context rot and keeping tool selection accurate as they scale.
Tool orchestration is just scratching the surface of context engineering. Follow my exploration on LinkedIn, and if you want to experiment with these ideas yourself, check out our Docs and SDKs.
More resources

Engineering
– 8 min read
Avoid context rot and improve tool accuracy for AI agents using MCP

Dennis Thompson