Thought leadership
– 11 min read
RAG vector database explained
Key benefits & limitations for ML projects

Ksenia Anske | September 23, 2024

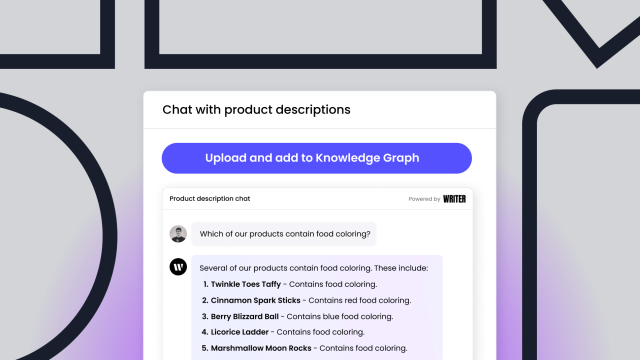
RAG vector databases boost LLMs by integrating timely, relevant data, improving response accuracy and relevance. They use KNNs to query data and segment it into manageable embeddings. Due to issues like imprecision and high update costs, RAG vector databases prove to be a challenge to implement for enterprise environments. Our graph-based RAG solution, Writer Knowledge Graph, simplifies integration and improves accuracy in ML projects. Check out our Knowledge Graph API guide.

Generative AI is quickly becoming the go-to for enterprises wanting to tap into their wealth of internal data for company-specific question-answering and analysis in real time. But here’s the thing: relying only on large language models (LLMs) doesn’t cut it. LLMs are great, but they’re primarily trained on public data, so they don’t understand your company’s specific knowledge. True intelligence doesn’t come from just adding more training data or building a more sophisticated model — it comes from augmenting the model with relevant, real-time data using smarter retrieval.
That’s where retrieval-augmented generation (RAG) steps in.
RAG is all about finding the right data to answer a question and feeding it to the LLM. The traditional method for this is vector retrieval, which works, but it’s far from perfect — especially in large, complex ML projects.
Let’s take a look at the key benefits and limitations of RAG vector databases. We’ll also go over why graph-based retrieval may be the key to making generative AI work for enterprise use at scale.
What’s a RAG vector database?
At its core, a RAG vector database uses vector retrieval to locate relevant data for the LLM to process. This method involves breaking data into smaller vector embeddings and then matching a query with the closest vectors using algorithms like K-Nearest Neighbors (KNN). While effective for general use cases, this traditional approach has limitations when applied to large-scale machine learning (ML) projects.
Limitations of vector retrieval in RAG
Using vector retrieval in a RAG vector database can sometimes feel like using a sledgehammer to crack a nut. It’s powerful but not always precise. Vector databases store numerical representations of data, but they don’t always capture the nuances or relationships between data points — leading to issues when handling complex, interconnected enterprise data.
For example, let’s look at keyword searches in a phone company’s internal database.
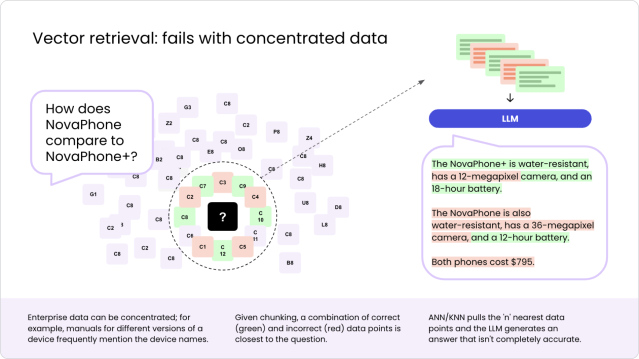
If you search for “comparison between NovaPhone and NovaPhone+,” vector retrieval might pull up documents that mention both models. But because these documents often use similar terms, vector retrieval might not get it right, confusing similar features or mixing up the two models. This is a problem with RAG because the information it finds can be a mix of correct and incorrect data points, leading to answers that aren’t completely accurate.
Given these limitations of vector retrieval, it’s important to understand the underlying mechanisms of a RAG vector database to see why these problems arise. Let’s look at how it works and explore its shortcomings in handling complex enterprise data scenarios.
How a RAG vector database works and why it falls short in enterprise use cases
So what leads to this confusion? The answer lies in the process of how a RAG vector database functions:
- Data processing: Data is split into chunks (100–200 characters each) and converted into vector embeddings. For example, the word “cat” might be represented as [1.5, -0.4, 7.2, …], turning text into a numerical form that algorithms can process.
- Query and retrieval: Your query is turned into a vector, and algorithms like KNN or Approximate Nearest Neighbors (ANN) retrieve closest matches.
- Answer generation: The LLM pieces together an answer from the top “k” matches.
Sounds straightforward, right? But here’s where RAG is limited. Chunking data into small pieces can lose context — imagine reading a book where the pages are shuffled. Plus, KNN/ANN algorithms aren’t always efficient or accurate when dealing with large, complex datasets.
Finally, there are the issues of rigidity and cost. Every time you need to add new data, a vector database can’t just append it to the existing data set. It needs to rerun all the data and assign each data object a new value. This is because what is in the entire dataset determines what value is given to each vector embedding. And every time you change your embedding model, it costs money. The larger the corpus of data your company has, the more it’ll cost.
With new data added every day, an enterprise environment demands a more dynamic, flexible, and affordable solution.
Graph-based retrieval: a smarter alternative for RAG
Graph-based retrieval offers a more sophisticated approach to RAG. Instead of simply looking at the distance between data points, it builds a web of relationships between data points. Each data point becomes a node, and its relationships to other points become edges.
Here’s how it works:
- Data processing: Entities are represented as nodes, and relationships are represented as edges. The edges can be used to show how the nodes are related. For example, a graph of a customer database could include a node for each customer, and edges to represent their purchases.
- Query and retrieval: Graph-based retrieval uses a combination of NLP algorithms, heuristic algorithms, and ML techniques to understand the context of the query and identify the most relevant entities and relationships.
- Answer generation: The LLM then takes those relevant data points and formulates an answer. By storing data in a cost-effective and easily updatable graph structure, semantic relationships are retained, resulting in accurate retrieval of relevant data for each query. Advanced retrieval techniques and LLM enhancements can further improve accuracy and reduce hallucinations.
With graph-based retrieval, you’re not just finding the closest match — you’re finding the right match by understanding the deeper connections within your data. This method reduces the limitations of RAG when applied to complex, enterprise-level ML projects.
Why building a graph-based RAG system is challenging
Building a custom graph-based RAG system from scratch can be resource-intensive. Here’s what you’d typically need to do:
- Data setup: Organize your data into nodes and edges, representing entities and their relationships, using tools like Neo4j or Amazon Neptune.
- Query and retrieval: Implement Natural Language Processing (NLP) and ML algorithms to understand user queries and find relevant data points.
- Scaling and maintenance: Ensure your system remains efficient as your graph database grows by adding new data, updating relationships, and running retrieval queries in real time.
- Deployment: Fine-tune the system’s ability to respond to different types of queries while optimizing retrieval speed.
In other words, it’s a big task. That’s why many developers look for pre-built solutions to avoid the complexities of building graph-based retrieval from the ground up.
The Writer Knowledge Graph: a pre-built solution
At WRITER, we’ve already recognized the challenges of building a graph-based RAG system from scratch. That’s why we built the Writer Knowledge Graph, a ready-made solution that takes care of the heavy lifting. With our API, you can easily integrate graph-based retrieval into your ML projects.
Here’s how to use the Writer Knowledge Graph API:
1. Create a Knowledge Graph: Organize your data into nodes and edges — but without the hassle of setting up graph databases.
For example:
# Assumes that there is a Writer client instance
# stored in `my_client`.
def create_knowledge_graph(graph_name, client):
"""Creates a new knowledge graph and returns its id."""
return client.graphs.create(name=graph_name).id
# Create a new KG named "My Knowledge Graph"
# and display its graph ID.
graph_id = create_knowledge_graph("My Knowledge Graph", my_client)
print(graph_id)2. Upload files: Upload PDFs, spreadsheets, or text documents using the Writer SDK without worrying about compatibility or manual data parsing.
For example:
import os
def upload_file(file_path, client):
"""
Uploads a single file (specified by pathname)
and returns its id.
"""
# Open and read the file's contents
with open(file_path, 'rb') as file_obj:
file_contents = file_obj.read()
# Upload the file
file = client.files.upload(
content=file_contents,
content_disposition=f"attachment; filename={os.path.basename(file_path)}",
content_type="application/octet-stream",
)
return file.id
def upload_files(file_paths, client):
"""
Uploads a list of files (specified by pathnames)
and returns a corresponding list of ids.
"""
file_ids = []
for file_path in file_paths:
file_ids.append(upload_file(file_path, client))
return file_ids
# Upload three files to Writer and get their file IDs.
files = [
"./files/My Brochure.pdf",
"./files/Additional Notes.txt",
"./files/Supplementary Data.csv",
]
file_ids = upload_files(files, my_client)3. Associate files with the graph: Link uploaded files to the graph for retrieval operations.
For example:
def associate_files_with_graph(file_ids, graph_id, client):
"""Associates a list of files with a graph."""
for file_id in file_ids:
client.graphs.add_file_to_graph(graph_id, file_id=file_id)
# Associate the files uploaded in the previous example
# with the graph created in the earlier example.
associate_files_with_graph(file_ids, graph_id, my_client)4. Integration with no-code AI apps: Once the Knowledge Graph is created and files are uploaded, you can use it in no-code apps built with AI Studio. These apps can also be embedded in Writer Framework apps.
Real-world applications of graph-based RAG
Here’s how graph-based retrieval can be applied to real-world scenarios:
- Customer support systems
Quickly resolve customer queries by linking historical tickets, product details, and policies. This speeds up response times and improves accuracy.
Read more about customer support systems here. - Sales enablement
Equip sales teams with instant access to market data, product insights, and competitor analysis, improving decision-making and boosting sales velocity.
Learn more about sales enablement here. - Financial advisors
Financial trend analysis and client personalization become easier using Knowledge Graphs to retrieve relevant financial insights.
Explore financial advising here.
Simplify your RAG setup with Writer Knowledge Graph
Smarter retrieval, like graph-based RAG, isn’t just about finding the closest match — it’s about finding the right answer. With the Writer Knowledge Graph, you can skip the complexity of building a system from scratch and start building truly intelligent enterprise AI.
Ready to dive in? Start with our Knowledge Graph API guide and see how you can implement smarter retrieval. Let us know what you build! 🚀