Product updates
– 11 min read
From Months to Minutes: Rebuilding Our AI Infrastructure for Scale
Writer Team | December 11, 2025

As customer demands for model choice, guardrails, and observability grew, our infrastructure needed to keep pace. The solution wasn’t to patch the old system—it was to build something entirely around new principles: Build, Activate, Supervise.
- Writer’s legacy Content Generation system required weeks of custom coding for each model provider integration, creating significant bottlenecks as customer demands for flexible model choice and observability grew across hundreds of companies.
- The new LLM Gateway replaces hard-coded integrations with dynamic, database-driven configuration, enabling engineers and customers to add supported models in seconds through a self-service admin panel without deployment pipelines.
- Built around Build-Activate-Supervise principles, the framework lets technical teams bring their own models, deploy inference anywhere within the platform or via SDK, and oversee agent behavior with complete visibility.
- Key improvements include instant configurable guardrails, real-time request tracking with full context logging, encrypted credential rotation without downtime, and backward compatibility ensuring existing agents work unchanged.

As part of our recent launch of new agent supervision features in AI Studio, we embarked on a major backend migration involving how we route LLM calls at WRITER. If you’re an engineer, you know the pain of making a big change to how things work at your organization. Migration causes headaches across the org no matter how many advantages new architecture brings to the table. Your team, like ours, is going to come to you with questions and demand answers.
WRITER began working with generative AI five years ago, before the technology was well known. As LLMs, models, and agents evolved, so did our approach. Without best practices to draw on, everything we created was bespoke. Recently, however, we made the decision to rearchitect our approach to AI inference, laying a new foundation based on what we and the broader industry have learned and developed since 2020. We think this approach not only improves our capabilities today, but provides a foundation for us to keep pace with this rapidly changing technology far into the future.
Below, we’re going to walk through changes we’ve made, explain how these updates address key pain points, and why it was worth the effort of building and migrating to a new approach.
The Evolution of the Content Generation service
Users and automated agents on the WRITER platform all need access to AI inference, but different tasks require different solutions. To ensure a good experience, we wanted to offer a consistent user interface, regardless of the inference type or provider.
For years we used a service called Content Generation as our in-house LLM integration gateway. It handled the work of routing requests to multiple models, which we hosted on a small number of hand-selected inference provider platforms with minimal administrative overhead and interaction.
The choice of inference providers was a task not undertaken lightly. We did our best to consolidate to a few providers and hard-coded the integrations with those providers so that the routing service was a rock-solid foundation our users could depend on.
For a long time this approach served all of our LLM completion needs, but as we’ve added more providers, we began to hit a wall. The integration for Bedrock, for instance, took much longer than we anticipated and proved to be pretty complex to manage.
Since different inference solutions do slightly different things, they might all have their own quirks and ways of being used. If a developer or an automated agent had to learn a new way to interact with each provider, it would be a nightmare: slow, error-prone, and just plain annoying.

This gif shows the entire evolution of the Content Generation service from start to finish using Git history. Each cluster of circles represents a code file under a particular path within content-generation. As the days go by, we see new lines connecting the clusters that represent the tree of directories within the service. When major changes are made, many circles are added, removed, or moved to a different branch in the visualization. As you can see, the complexity of the project greatly expanding over time.
Our new approach
Our solution to this growing complexity is something we call an LLM Gateway. This service acts like a universal remote control: providing a single, consistent, and easy-to-understand way to talk to all those different providers, even though they’re different under the hood.
Instead of a hard-coded approach, it uses ready-built libraries and dynamic database-driven configuration to allow us to add new providers at an unprecedented pace.
The goal with LLM Gateway was to learn from our struggles with Content Generation and design something from the outset to support the interactive Build, Supervise, Activate lifecycle at scale:
- Build: Allow technical folks like engineers and IT admins to bring their own models and providers
- Activate: Deploy the use of inference anywhere, whether within the WRITER platform in out-of-the-box Agents, playbooks, and Agent Builder agents, or embedded within customer software through the WRITER SDK.
- Supervise: Ops and product managers can view usage, make decisions and secure the inference experience using pre-existing guardrails, custom security, new metrics and logs, and third-party observability tool integrations.
Let’s walk through these three areas and explore how the upgrade to LLM Gateway will allow WRITER’s technical teams to be faster and more efficient, while empowering our customers to make changes on their own that used to require custom work on our end.
Faster model integrations
As our user base expanded and WRITER began supporting thousands of agents across hundreds of companies from varied industries, we saw that customers needed the flexibility to call different models. This might be a decision based on security, speed, cost, latency, accuracy, or domain expertise. Whatever the customer needs are, we need to provide that flexibility without compromising the experience.
From a model gateway perspective, that means that we need custom request and response converters, error handlers, security, and tool integrations. With our Content Generation system, all of this was hand coded. It worked, but our development velocity needs to be measured in hours and minutes, not days and weeks.
With our old approach, customers couldn’t add models themselves. They had to wait for us to add and test a new model or provider integration. Some models supported automatic failover , but enabling it always required new code changes and a full deployment pipeline. And because we maintained our own provider adapters, we also had to translate provider specific error messages into WRITER’s standard error format for use across the platform.
In LLM Gateway, if the model provider is supported, our internal engineers or customers can add it in seconds through the admin panel. If they have a model on Bedrock that they’re using elsewhere, they can put in the credentials and model id, connect it, and use it in their agents as soon as they click save.
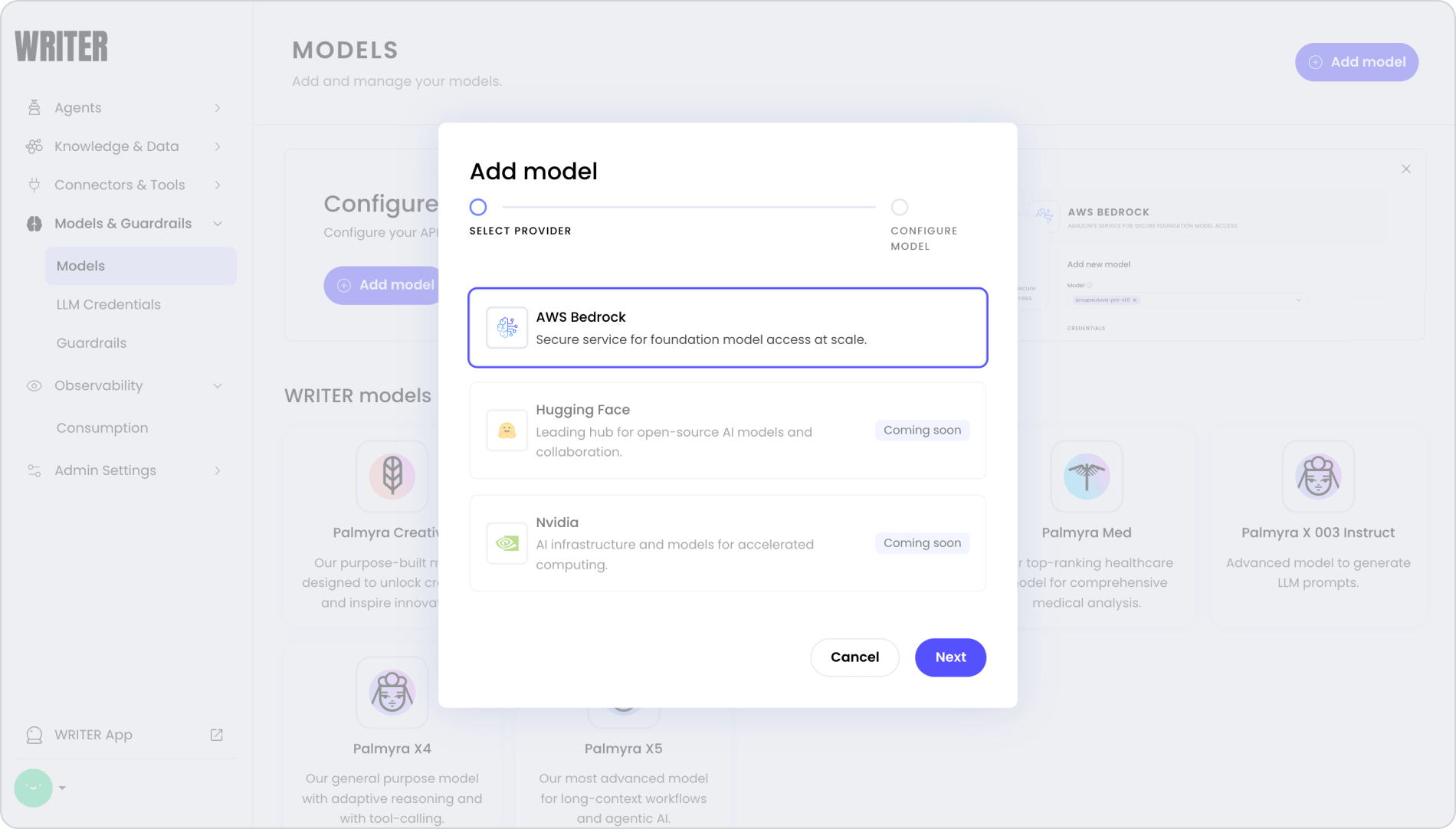
It’s also highly available by default with multiple replicas. All model health checks are run regularly throughout the day. If a model is unavailable, we’ll know about it. We also do load balancing across the replicas and across the models.
We can change the model, update the config, and make an instant switch. This means when we’re working on models, we can iterate more rapidly.
Importantly, customers can do this without WRITER ops redeploying the service and without having to promote slowly all the way from dev to test to prod. They can bring their own model and we don’t need to manage all of that infrastructure for our customers to activate it.
Making this process faster and easier also means we can test different versions of models by doing different traffic splitting and load balancing to models within the system. Writing custom providers will be rarer and we’ve consolidated everything to work off of one OpenAI-compatible API, which has become an industry norm.
With LLM Gateway up and running, we switch from waiting on WRITER engineering to deploy a model integration to a self-serve system.
Guardrails
First, a quick primer: in the context of agentic AI (systems that can take action, use tools, and make decisions), guardrails are essentially a safety layer or “middleware” that sits between the application and the AI model. They act as a distinct, programmable firewall that intercepts and evaluates both what goes into the model (user prompts) and what comes out (agent responses or tool calls) before they are executed.
In the Content Generation era, guardrails were something we had to hard-code for each provider, including the full testing cycle and promotion to prod. They were inconsistent and it was very difficult to get through quickly. Verifying them takes a lot of time. They were usually set up within the confines of the model provider and we had no control over whether that happened pre- or post-call. They most often just rejected things and we couldn’t enable or disable them without manually disabling them in code.
That’s now a thing of the past. With the new system, we have added configurable guardrails. Customers can take guardrails they’ve already tested, and enable or disable them at need. Internal WRITER ops personnel can do the same thing with guardrails we’ve developed and tested in-house. Guardrails that work on one platform can be combined to work with models hosted on other platforms. They can act to make transformations before or after a provider makes a completion, giving us both pre-call and post-call safety.
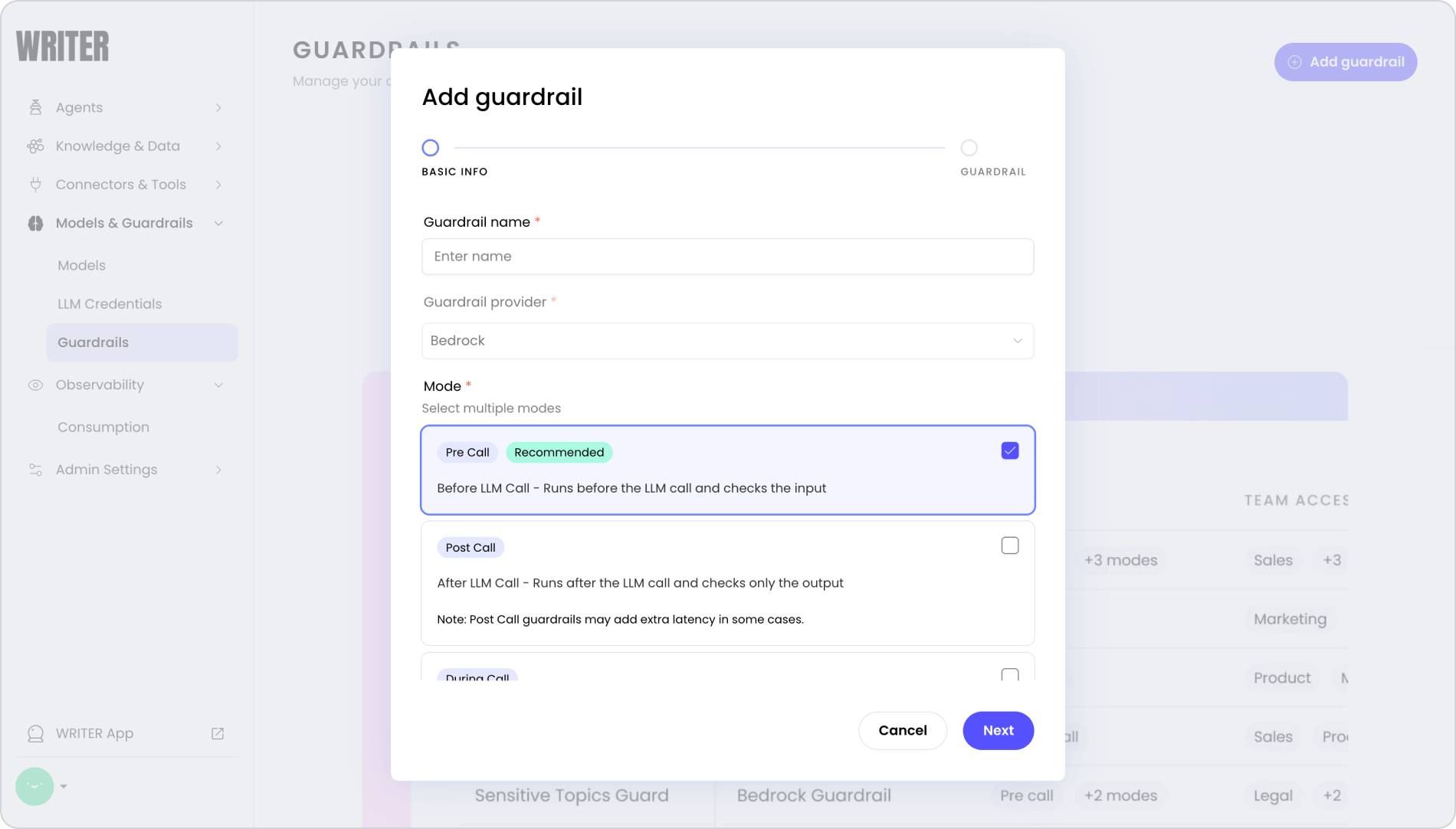
Supervision
What we wanted, at a high level, was full visibility into all LLM traffic so we and our customers could understand every request and its corresponding response, how they were billed, what credentials were used, and where errors may have occurred.
With that in mind, we set out to rebuild our inference approach with a clear list of goals:
- Real time tracking
- Quick guardrails configuration
- Ability to swap credentials for models without downtime
- A complete audit trail of the who, what and when that happens
Before the introduction of the new LLM Gateway, logs were scattered across multiple places, and we generally didn’t have correlation once it went out to a model provider. That meant it took a long time to figure out what went wrong. For something like credential rotation, we had to go into our infrastructure secrets, update the secret there, to make a PR in k8s, refresh that PR, and then wait for it to get through deployment.
For our customer, it’s critical to have an audit trail from our logs. It was limited with Content Generation and required manual effort to search through GCP, AWS CloudWatch, or Grafana to reconstruct what happened when a request occurred. With LLM Gateway, we are logging every request with its full context: the org, the team, the user, the model, the cost latency, session, action id, everything that we can collect.
We’re working on adding observability features so that customers can export all of that information through Prometheus metrics and OpenTelemetry.
Since we’re enabling third party models and guardrails, we also need to store credentials. That’s not going to work unless that credential storage is dynamic.
LLM Gateway stores credentials encrypted, and we can rotate without having to restart the service. They’ll never be logged, exposed in the APIs or in logs, or in any of the things we send downstream for processing.
In the old system, we had separate billing. With LLM Gateway, we can track our costs directly and in real time. It’s per request and can be aggregated by the org, team, user, or model. We can set budget limits and alerts on all of those levels. The logs will be clearly visible in the customer admin UI and we won’t have to hand-aggregate all that data inside of the billing app.
Where we go next
LLM Gateway adds reliability and makes it easier for customers to write less code to build their agents.
It also gives us a platform we can optimize for latency to give us fast response times. We’re caching repeated requests, pooling connections, and using async, non-blocking requests.
Want to add a model? You don’t need to deploy something through the platform. Just add or change a configuration and it’s instantly available if it’s healthy. Want to update guardrails or rotate credentials? Again, no restart required; these changes take effect immediately. Best of all, any existing customer agents don’t have to change anything. All agents that work today will continue to work through LLM Gateway.
Zooming out, this new infrastructure doesn’t just solve today’s challenges; it gives the WRITER platform the flexibility to support evolving customer requirements as they grow in complexity and scale. By rebuilding inference around reliability, configurability, and real-time supervision, we’ve established the platform principles behind Build → Activate → Supervise, letting teams develop agents faster, move them into production with less friction, and oversee their behavior with full visibility.
To learn more about integrating Bedrock models to WRITER, check out the docs
Learn more about building and supervising agents in WRITER