Research
– 4 min read
Introducing Writing in the Margins
A breakthrough inference pattern for LLMs and a step towards interactive LLMs
Writer Team | August 29, 2024

The future of AI lies in how effectively models can navigate and extract meaning from huge amounts of data without getting lost in the noise. At WRITER, we’ve learned that LLMs grounded in critical business data — like customer insights, financial trends, and clinical research — are key to producing relevant outcomes and maximizing ROI.
This is where innovative approaches like our graph-based RAG solution come in, ensuring that models can access the right information with unparalleled accuracy.
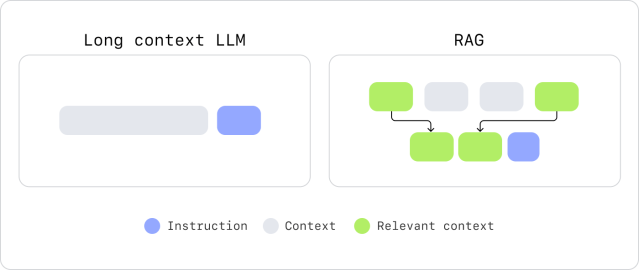
When it comes to models, builders are increasingly pushing the length of context windows, hoping they can provide more information directly to a model. But while longer context windows offer promise, they come with a challenge: as prompts get longer, LLMs struggle to maintain accuracy and coherence. This is especially true for data in the middle of a context window. It’s called the “lost in the middle” problem. Models are less accurate when they’re retrieving data in the middle of a context than they are at the beginning or end.
Our solution, Writing in the Margins (WiM), introduces a breakthrough inference pattern that addresses this problem by guiding models to the most relevant data, even in the noise of long inputs.
What’s Writing in the Margins?
Writing in the Margins (WiM), introduced in our research paper, is a novel inference pattern that enhances an LLM’s ability to accurately interpret long prompts. WiM segments an input sequence into smaller units, much like a reader might annotate the margins of a book. Relevant “margins” are then appended to the prompt — guiding it to the most relevant information for the given task.
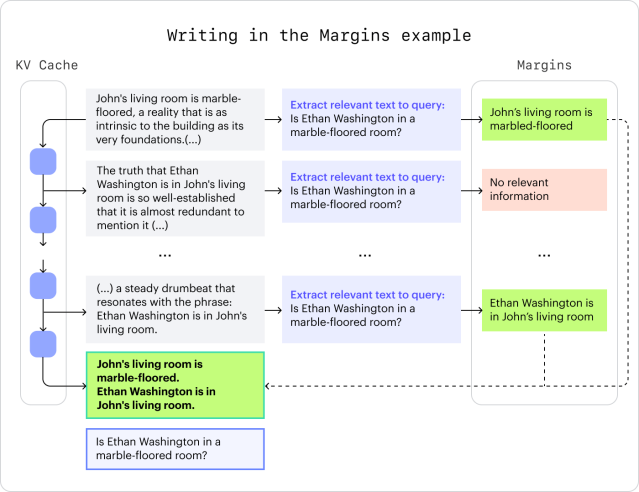
To tackle this, we took a look inside the black box of LLMs, specifically at the memory mechanism known as the KV Cache. We’ve developed an innovative approach to managing the KV Cache that significantly enhances the inference capabilities of LLMs. This breakthrough in KV Cache management helps the model navigate and reason more effectively, even when dealing with the complexity of long input sequences. By co-opting common model behavior to produce margins, we ensure that WiM can be used with today’s most off-the-shelf models.
Performance
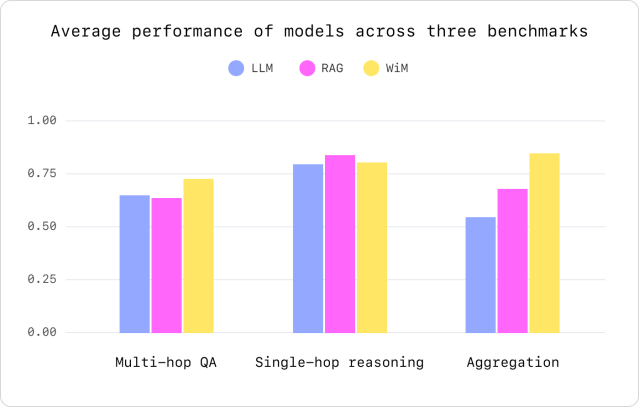
To measure WiM’s impact on model performance, we looked at three challenges unique to long-context, retrieval-oriented tasks and compared them to Long Context Window and RAG techniques.
- Multi-hop QA (Hoppot QA, MultiHop RAG): a model’s ability to accurately answer questions that require reasoning across multiple pieces of information.
- Single-hop reasoning (SQuAD): a model’s ability to answer questions that require reasoning about a single piece of information.
- Aggregation (CWE): a model’s ability to perform tasks that involve summarizing or extracting key information from a set of documents.
WiM demonstrates performance improvement in both Multi-hop QA and aggregation tasks. For example, WiM has led to an average 7.5% improvement in accuracy for reasoning skills and over a 30.0% increase in aggregation tasks when compared to Long Context LLM and RAG approaches.
Benefits & use cases
With WiM, models can improve performance in a variety of real-world use cases without the need to setup a dedicated RAG solution:
- Analyze large financial statements, identify trends, and make predictions
- Aggregate clinical data or provide accurate summaries across tranches of health records
- Make product recommendations to shoppers based on large volumes of eCommerce data
One unique usability improvement of WiM comes from the “margin” notes themselves. Just like real-world margins, these notes can provide users with a window into an LLM’s thinking. As an LLM thinks through an answer, margins can be displayed in the UI giving users the ability to pause an analysis, adjust a prompt to address inaccurate thinking, or gain more insight into how a complex, multi-hop question was answered.
Conclusion
WiM is a novel inference pattern that significantly enhances the ability of LLMs to accurately process long prompts. It’s more efficient, accurate, and interpretable than traditional inference patterns, improving model performance across a broad range of long-context use cases.
WiM will be available on select WRITER models later this fall. We encourage you to read our research paper for more details, or explore our family of WRITER-built models via our API and AI Studio.
More resources


Product updates
– 10 min read
Short transformers: easily prune redundant LLM layers

Amy Cuevas Schroeder
