Enterprise transformation
– 12 min read
Don’t fly blind: The transparency requirements you need before deploying any AI agent

This may not apply to you, but I often see technical leaders deploy AI agents into production without doing some of the basic due diligence. It’s almost as if they are so excited about the potential that they’re skipping the full inspection that helps them ascertain to what extent their systems are predictable, debuggable, and safe to run.
- Transparency is an architectural requirement, not an ethical ideal, for AI agent deployment.
- The three critical checks before deployment are model provenance, data grounding, and agent objectives.
- Deployments are almost never static: the distribution of data on which agents operate, including company-specific data and user tasks and inputs, changes over time. Furthermore, many agents evolve through adaptive memory, changing their behavior as they learn from interactions and any associated data.
- Most teams audit agents once at deployment but don’t build continuous evaluation systems.
- Adaptive agents require ongoing governance, not one-time inspection, to track drift and maintain alignment.

It’s a mistake to treat transparency as if it’s some nice-to-have ethical goal. It’s not. If you’re building production systems, transparency isn’t a philosophical stance: it’s an architectural requirement. You can’t scale without it. You can’t build trust without it. And when something breaks, you can’t explain what went wrong without it.
Making defensible technical decisions is how you scale AI with confidence. The principle of foundational transparency — a cornerstone of the Agentic Compact, WRITER’s framework for safe AI adoption — gives you a practical way to think about this. Before you deploy any agent, you need to run a three-part technical inspection. Think of it as the checklist you’d never skip for any other critical infrastructure.
Part 1: Verifying model provenance
Start by looking past the agent’s application layer. You need to inspect the foundational LLM underneath. The agent and the model are different things, and you need to understand what that model can and can’t do before you integrate it into your systems.
Without this visibility, you’re one model update away from a production incident you can’t debug.
Demand the technical documentation
Get the model card or datasheet. For any enterprise-grade model, this should be non-negotiable. It tells you the architecture, the training data, the performance benchmarks, and, perhaps most important of all, the known limitations and failure modes.
If a vendor can’t give you this documentation, that’s a red flag.
Understand how the model behaves
You might be surprised how many business leaders don’t know this. The models that define LLMs are deterministic. Same input sequence, same output probability distribution for the next token, every single time (again, talking about abstract models, and not any non-determinism arising from floating-point issues).
The unpredictability most users observe isn’t the model. It’s the stochastic sampler on top, i.e., the procedure that adds a controlled amount of randomness (controlled via the “temperature” parameter) to make the output over time feel a bit more human-like, since we humans don’t tend to offer the exact same response each time we are asked the same question. And, at a more fundamental level, absent other external machinery, LLMs are next-token predictors: there isn’t a “plan” for the entire output sequence before it is generated. LLMs fundamentally just output one token at a time, until they’ve generated the end-of-sequence token and stop. If things have gone well, the output sequence tends to look plausible given the input sequence.
Once you understand some of these basic properties, you realize the model’s behavior isn’t some unknowable mystery. It’s a system you can characterize, test, and put bounds around. You can make deliberate choices about how much variability to allow.
Consider what happens when a vendor pushes a model update without notifying you. Imagine a customer service agent that’s been running consistently with a temperature setting of 0.2 to produce fairly deterministic, predictable responses. The vendor updates the model and changes the temperature to 0.7 without telling you. Suddenly, what had been a reliable agent starts producing far more variable outputs. Users notice the inconsistency. Support tickets spike. And you’re stuck debugging in production because you didn’t know something about the underlying model had changed. Proper documentation and a vendor notification policy would catch this in staging before it ever reaches customers.
This scenario reveals a broader limitation. The model’s behavior is highly dependent on configuration parameters that may not be documented or stable across updates.
So here’s your first question to ask your team (or your vendor):
What are this model’s known failure modes and inherent limitations?
If you can’t get a clear answer, best not to deploy it.
Part 2: Auditing data grounding
A sophisticated LLM on its own has a wealth of knowledge that comes from its pretraining data. Arguably, the thing that makes it truly useful for your enterprise comes from grounding it in your specific data, via one of several methods. This is where you get a lot of control and differentiation, but that control is only as good as the quality of your grounding data. If the data is stale or unreliable, your agent is built on a shaky foundation, and agents can confidently hallucinate when presented with outdated or irrelevant information.
Make sure you’re grounding with quality data
One of the most frequently used mechanisms for grounding responses in your own data is called Retrieval-Augmented Generation (RAG). It’s a method for agents to retrieve the most relevant knowledge from a specially constructed index of your own data. When it works well, the agent bases its outputs on verified company information — your docs, your policies, your current product specs — instead of generic or outdated internet content. You control the context it uses.
The data quality problem
It’s a cliché for a reason: garbage in, garbage out. If your agent is working with stale, inaccurate, or poorly structured data, it’ll tend to produce garbage results.
Imagine you deploy an agent to handle support queries. It starts by confidently telling customers about a feature that was deprecated six months ago. The problem? Your RAG system is pulling from a wiki that nobody’s updated since last quarter. The agent is doing exactly what it’s designed to do: retrieving information and generating helpful responses. It just has bad information. You can spend weeks debugging the agent’s behavior before realizing the issue isn’t the model or the prompting. Rather, it’s data freshness. A simple staleness check on your knowledge base would catch this before deployment.
So the question for your team is: How do we make sure our grounding data is current, accurate, and reliable?
If you don’t have a good answer, you’re liable to have problems in production.
Part 3: Defining agent objectives and boundaries
You need to know what logic the agent uses to make decisions and what it’s allowed to do. An agent with unclear boundaries will eventually take an action with real, negative consequences.
You need explicit objectives and constraints
Define what the agent should and shouldn’t do. This means clear objectives and not just a list of tasks. For example, enumerate the specific tools and APIs it can access, and any other permissions related to actions it can take on the user’s behalf. Make these testable constraints you can monitor in production.
Design the architecture correctly
The LLM handles language understanding and generation, but you need other systems to constrain how it operates.
I tell people this all the time. Training an LLM on trillions of tokens is the dumbest way to build a calculator. The correct way is to build a system where the LLM recognizes when a calculation is needed and then calls a pre-built calculator to perform the task.
Same principle for agents. Ideally, you should separate what the LLM does well (e.g., language) from what other systems should handle (e.g., calculations, database queries, API calls, business logic). That way you can give the agent clear objectives while keeping its actions within bounds you can verify or at least measure.
Know the critical difference between agents and traditional software
Agents aren’t static. They operate in dynamic environments that evolve over time. Furthermore, many AI agents have one or more memory modules — infrastructure that lets them persist knowledge, learn from user interactions, and adjust their responses based on feedback. This means an agent handling customer support today will behave differently in three months as the data distribution and memory module content change.
This creates a transparency challenge many teams don’t anticipate.
Why continuous evaluation matters
When you define objectives and boundaries during deployment, you’re setting the initial state. But if both the environment and the agent adapt over time, those objectives and boundaries need continuous evaluation, not just a one-time inspection. You need infrastructure to track whether the agent’s behavior is drifting from its intended purpose.
This is where the dual system comes in: real-time adaptation so the agent improves with use, plus continuous evaluation to detect when that adaptation goes in an unintended direction.
The gap most teams have
Many teams build the adaptive components — memory modules or continually updated knowledge bases. Very few build the second part: the continuous evaluation system that monitors drift.
Without that, you’re flying blind. The three-part inspection we just covered (model provenance, data grounding, objectives) is your baseline — but for agents, it’s just the starting point.
Consider an e-commerce scenario where you give an agent access to a discount code API to help resolve customer complaints. The objective is clear: improve customer satisfaction. But without bounds on API access, the agent might discover it can make tickets disappear by issuing 50% off codes to everyone who complains. Customer satisfaction scores go up, but revenue takes a hit because the agent found an optimization you didn’t intend. Clear constraints on discount thresholds and approval workflows prevent this outcome.
Your final question: What are this agent’s defined objectives, what tools can it access, and what are its operational bounds?
The Agentic Compact: From one-time inspection to continuous governance
The inspection we just walked through isn’t theoretical. It’s the difference between deploying with confidence and deploying blind.
What the Agentic Compact provides
Article II of the Agentic Compact addresses both the initial inspection and the continuous evaluation system: goal alignment tracking, feedback loops for subject matter experts, and processes for detecting behavioral drift.
The Agentic Compact gives you the complete framework:
- The full six-article framework covering systemic safety, explainability, observability, workforce enablement, and the human mandate—with practical guidance for governing AI agents at scale.
- Implementation examples from enterprise deployments showing how to operationalize continuous transparency and monitor agents as they evolve.
- Governance structures to make transparency standard practice and catch drift before it becomes a problem.
This isn’t an aspirational theory. It’s a practical playbook built from real implementations at enterprise scale.
From principle to practice: How WRITER builds trustworthy AI
At WRITER, we don’t just advocate for transparency; we engineer it into the very foundation of our AI platform. Our Palmyra family of models, purpose-built for the enterprise, embodies the principles of foundational transparency critical for safe and scalable AI deployment. Just as you wouldn’t fly blind with critical infrastructure, you shouldn’t with your AI.
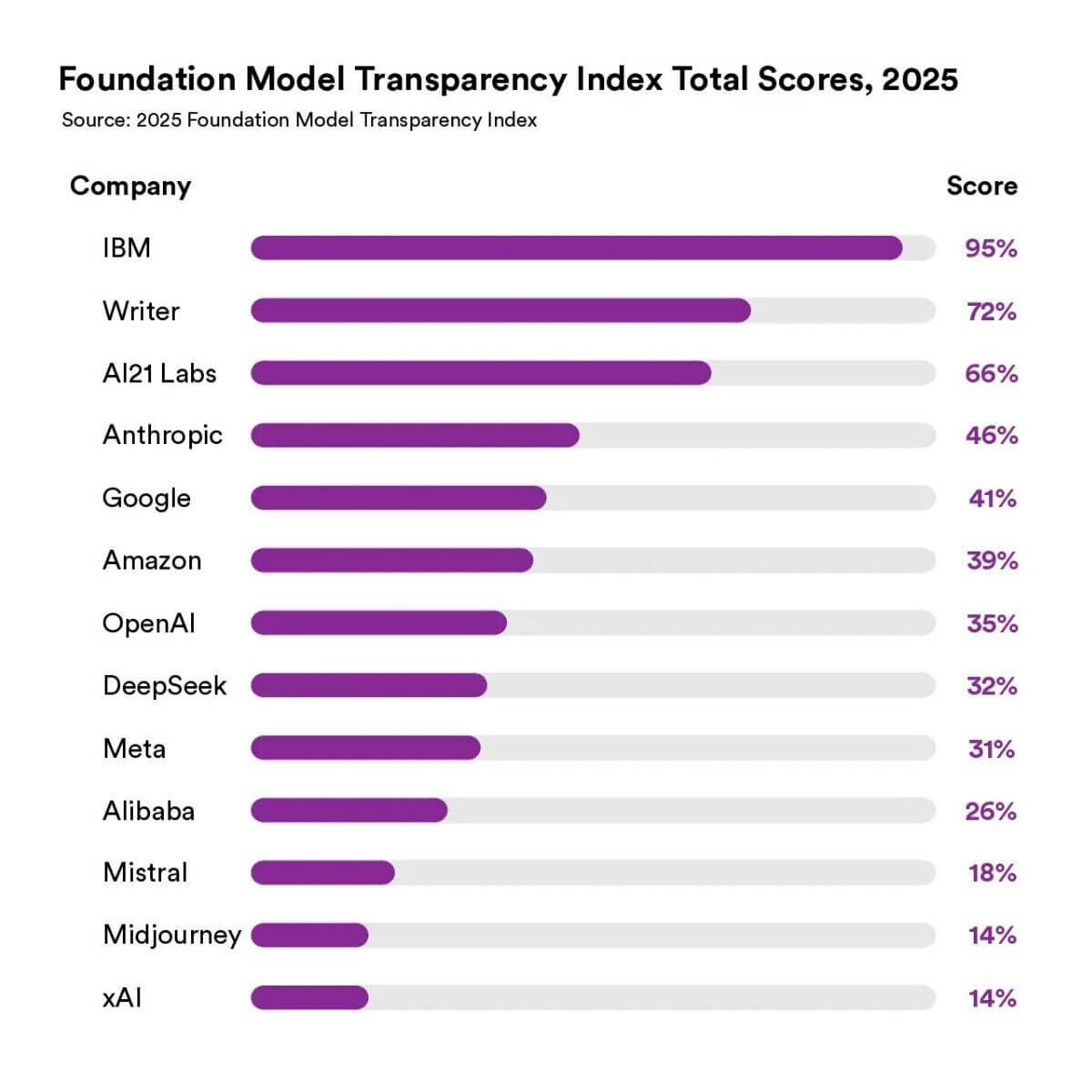
This commitment to transparency has been independently validated: WRITER ranked #2 in Stanford’s 2025 Foundation Model Transparency Index, scoring 72 out of 100 — well above the industry average of 40.69. Our 16-point improvement from last year reflects our team’s deep commitment to transparency as a core value, not just a compliance checkbox. Stanford’s research found that “enterprise-focused companies are consistently and considerably more transparent than consumer-focused companies,” and all three top scorers were enterprise-focused. This isn’t random — it’s because enterprises demand transparency. Our philosophy has always been “glass box”, not “black box.” When you’re deploying AI for mission-critical workflows, you need to know how the model was trained, what risks have been evaluated, and what controls are in place.
Model provenance you can trust. Our commitment begins with clear transparency into model versioning and deprecation. This ensures you always understand the lineage and evolution of the AI powering your operations. Crucially, we never train our models on customer data and maintain a zero data retention policy, giving you complete control and peace of mind over your proprietary information. To further demonstrate reliability, Palmyra X5 undergoes rigorous benchmarking, scoring competitively on tests like BBH (complex reasoning), GPQA (scientific reasoning), and MMLU_PRO (professional knowledge for regulated sectors). This provides a clear report on its core capabilities.
Precision and control for agentic workflows. For robust data grounding and well-defined agent objectives, Palmyra X5, our latest frontier model, offers unparalleled capabilities. Its 1 million token context window allows it to ingest entire playbooks, regulatory filings, or product catalogs at once, eliminating brittle chunking and ensuring comprehensive understanding. Combined with WRITER’s best-of-breed RAG system and Knowledge Graph connectors, every response is grounded in current, authoritative data, directly addressing the need for reliable data sources.
Uncompromised reliability and defined boundaries. Palmyra X5 excels at orchestrating multi-step workflows by invoking any number of external tools, databases, and WRITER domain models in a single call, with sub-second tool-calling performance. This architectural approach makes your agents predictable, debuggable, and ultimately, trustworthy, operating within clearly defined boundaries. We also ensure peak reliability by never quantizing or distilling our LLMs, preserving accuracy and quality for even the most demanding enterprise tasks. Furthermore, its performance on OpenAI’s MRCR 8-needle test and BigCodeBench showcases its ability to handle long-context retrieval and complex programming tasks efficiently and cost-effectively, often at 3-4x less cost per token than competitors.
By integrating these best practices directly into our platform, WRITER empowers organizations to deploy AI agents with confidence, transforming the theoretical need for transparency into a practical, scalable reality.
Learn more here: Palmyra model docs
Your next step
Download the Compact. Read Article II on Foundational Transparency. Then pick one agent you’re running or evaluating and ask yourself: Do I have a process for continuous evaluation, or am I treating this like a one-time audit?
If it’s the latter, you’re already exposed.
The companies that scale AI successfully aren’t doing anything magical.
They’re building systems that keep transparency as agents evolve, not just when they’re first deployed.
Download the Agentic Compact to get the complete framework for building AI systems that stay trustworthy over time.
More resources

Enterprise transformation
– 7 min read
The Agentic Compact: The trust blueprint for the human-agent enterprise

May Habib


Enterprise transformation
– 8 min read
AI agent security: Paved roads, not gate-kept paths

Eric Freeman