Inside WRITER
– 4 min read
HELM benchmark findings showcase Palmyra LLMs as leader in production-ready generative AI

At WRITER, we’re thrilled to announce the latest findings from the HELM (Holistic Evaluation of Language Models) framework, maintained by Stanford’s Center for Research on Foundation Models (CRFM). The HELM evaluation provides a comprehensive benchmarking of various language models, including our very own Palmyra LLMs. We’re proud to share that Palmyra has achieved outstanding results, solidifying its position as the leading, production-ready generative AI platform for enterprise.
- Palmyra LLMs, developed by WRITER, have achieved outstanding results in the HELM evaluation, solidifying their position as the leading generative AI platform for enterprise.
- Palmyra excelled in various scenarios, including open-book question answering, mathematical problem-solving, legal reasoning tasks, and medical question answering.
- Palmyra outperformed well-known models like Google’s Palm-2 and OpenAI’s GPT models in the Stanford HAI’s HELM Lite benchmark leaderboard.
- Palmyra’s scalability and specialized capabilities in legal, medical, and mathematical reasoning make it a versatile choice for enterprise-level AI applications.

Unveiling the Palmyra HELM benchmarking results
The HELM results have recently been updated to include a range of new models, among which is the latest release of our general-purpose Palmyra model. Palmyra has been evaluated across multiple scenarios, including open-book question answering, mathematical problem-solving, legal reasoning tasks, medical question answering, and more.
Let’s delve into some of the key findings:
- OpenbookQA: Palmyra achieved an impressive score of 0.938, securing the 2nd position for models in production. This scenario focuses on commonsense-intensive open-book question answering.
- MMLU: Palmyra excelled in knowledge-intensive question answering across 57 domains, tying for the 1st position in production with a score of 0.702.
- MATH – Equivalent (CoT): Palmyra showcased its mathematical problem-solving capabilities with chain-of-thought style reasoning, securing the top position in production with a score of 0.723.
- GSM8K: Palmyra’s mathematical reasoning on grade-school math problems earned it the first position in production with a score of 0.831.
- LegalBench: Palmyra demonstrated its prowess in legal reasoning tasks, securing the top position in production with a score of 0.709.
- MedQA: Palmyra’s performance in answering questions from professional medical board exams was commendable, earning it the first position in production with a score of 0.684.
- WMT 2014 – BLEU-4: Palmyra achieved a score of 0.262, securing the top position in translation among all models evaluated.
Understanding the results
As evidenced by Stanford CRFM HELM Lite benchmark leaderboard, Palmyra has emerged as the top-performing model for production use, surpassing even well-known models like Google’s Palm-2 and OpenAI’s GPT models. The only models to achieve higher scores than Palmyra were GPT-4 (0613) and GPT-4 Turbo. However, it’s worth noting that GPT-4 (0613) is currently rate-limited and will need to be distilled to reach its full potential for enterprise use. Additionally, GPT-Turbo is only a preview — OpenAI hasn’t revealed its plans for production use, leaving uncertainty around its performance compared to other models.
It’s also important to consider the potential limitations of compressed models like GPT-4 (0613) and GPT-4 Turbo. Research has shown that as a model is more compressed, performance drops. For example, GPT-4’s accuracy on an MMLU test dropped from 86.4% to their current 73.5% result.
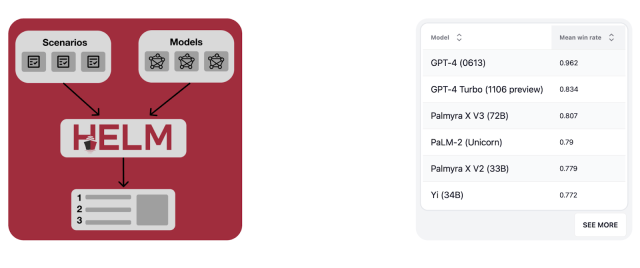
Palmyra, on the other hand, is designed specifically for production workloads, with 72 billion parameters compared to GPT-4’s 1.8 trillion. This scalability without the need for compression ensures that the performance demonstrated by Palmyra in the HELM evaluation is consistent with what users can expect in real-world applications.

LEARN MORE: Why larger LLMs aren’t always better for enterprise use cases
Furthermore, Palmyra excelled in specialized scenarios such as legal, medical, and mathematical reasoning, making it a versatile choice for various industries and use cases. Our specialized models, like Palmyra Med, maintain even higher accuracy than Palmyra for catering to a broader range of medical-related queries.
The power of Palmyra LLMs and the WRITER generative AI platform
These HELM findings highlight the unique approach we have taken in building generative AI technology at WRITER. Palmyra LLMs not only deliver exceptional accuracy but also offer scalability, making WRITER the preferred platform for enterprise-level AI applications. Combined with our accuracy-leading Knowledge Graph, graph-based approach to RAG (Retrieval-Augmented Generation), powerful AI guardrails, and flexible application layer, WRITER users have access to the tools they need to transform their work with generative AI.
To learn more about the HELM benchmarking results and explore the capabilities of Palmyra LLMs, schedule a demo with our sales team today.
More resources

Inside WRITER
– 10 min read
Palmyra LLMs empower secure, enterprise-grade generative AI for business
Alaura Weaver

