Innovation
– 10 min read
The limitations of vector retrieval for enterprise RAG — and what to use instead

Enterprises are increasingly adopting generative AI to tap into their company knowledge and data. However, simply relying on large language models (LLMs) alone may not provide the desired understanding of internal data. Because they’re trained on datasets gleaned from the public domain, LLMs on their own have a limited understanding of your company. To build powerful generative AI apps in the enterprise, you need to ground LLMs in your internal data.
Seeking to answer this challenge, data scientists and developers have started exploring various approaches to retrieval-augmented generation (RAG). RAG is the process of finding the right data to answer a question and delivering it to the LLM. The LLM can then reason and generate an answer.
A way to handle RAG is vector retrieval, which uses vector databases. It’s a robust method, but not ideal for enterprises. Let’s explore the concept of vector retrieval, its process, and its limitations in enterprise use cases. We’ll also cover a superior approach to RAG for enterprise use: graph-based retrieval.
- Vector retrieval in RAG relies on vector databases, which store vector embeddings of data objects.
- KNN/ANN algorithms measure the numerical distance between vector embeddings to define relationships between data pieces.
- However, vector retrieval has limitations such as crude chunking, inefficient KNN/ANN algorithms, dense and sparse mapping, cost and rigidity, and potential inaccuracies in the output.
- To overcome these limitations, WRITER has developed a graph-based RAG approach called the WRITER Knowledge Graph.
- The WRITER Knowledge Graph uses a specialized LLM to process data and build semantic relationships between data points, providing accurate retrieval of relevant data.
- Unlike vector databases, the WRITER Knowledge Graph is cost-effective, easily updatable, and supports various file types, making it a superior choice for enterprise RAG.

What problem does vector retrieval seek to solve?
Traditionally, keyword-based search has been used to retrieve answers to queries. In essence, an algorithm will search for information that contains the same words as those found in a query and provide the results.
But issues arise with keyword-matching in a natural language question-answering system, as the keywords in the queries don’t often match with the vocabulary used in the responses.
For example, if one were to search “looking for group social activities for cuisine enthusiasts,” a keyword-based retrieval system wouldn’t match with “cooking classes” or “food-tasting events.” The user will likely need to comb through a lot of irrelevant responses containing “group social activities” and “cuisine” to find any value in the information retrieved.
Knowledge retrieval with vector databases is a machine learning technique that bridges this language gap by searching for data with similar semantics, or concepts with related meanings.
How does vector retrieval work?
Any information retrieval process consists of three steps:
- Data processing: splitting data into smaller pieces and storing in a data structure.
- Query and retrieval: taking a query and retrieving relevant pieces of data to answer that query.
- Answer generation: sending relevant data to an LLM, which reasons and generates an answer.
Here’s how it’s done with vector retrieval:
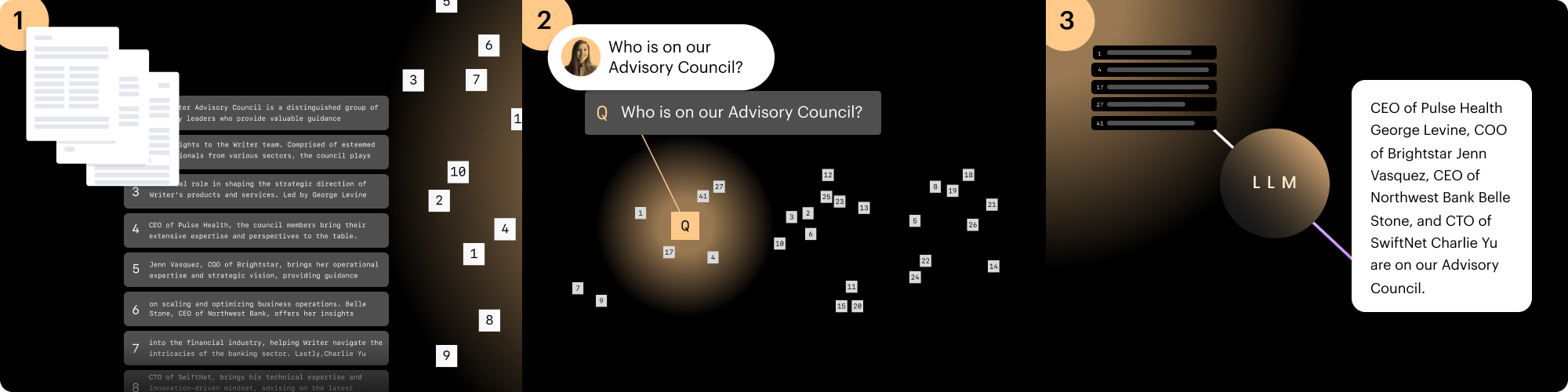
1. Data processing
First, data objects like text are split into 100 to 200-character chunks. It then converts each piece of data into a vector embedding, or a numerical representation. The vector embeddings are stored in a vector database.
Relationships between pieces of data are defined by measuring the numerical distance between the vector embeddings. Using our previous keyword query example, similar concepts like “food” and “cuisine” would be numerically closer to each other than “food” and “chairs.”
2. Query and retrieval
When a user asks a question, the query is also converted into a vector embedding. A K-Nearest Neighbors (KNN) or Approximate Nearest Neighbors (ANN) algorithm determines and retrieves the closest (“k”) data points to the query.
3. Answer generation
The top “k” vector embeddings are remapped back to the original pieces of data and sent to the LLM for reasoning and answer generation.
The limitations of vector-based retrieval
While vector retrieval has gained popularity, it comes with certain limitations that need to be considered in enterprise use cases.
Crude chunking methodology
Because LLMs have limited context windows, data is typically split into crude, 100- to 200-character chunks for embedding. This can result in the loss of context, as related pieces of data may be split apart.
Let’s say that the following chunk was retrieved for an LLM: “They began the prototyping process again with the substituted ingredient, sometimes flying in ingredients from America to perform their tests.”
While the sentence describes actions related to a prototyping process and ingredients, it lacks the context around it (in this case, a Wikipedia article about Mastering the Art of French Cooking). Neither a human reader nor an LLM would understand who “they” are, or why “they” were prototyping and testing with ingredients from America.
Additionally, vector embeddings only measure the similarity between pieces of data, lacking contextual information about their relationships.
Inefficient and inaccurate KNN/ANN algorithms
To measure and identify vector embeddings closest in numerical distance, vector-based database retrieval uses K-Nearest Neighbors (KNN) algorithms, originally developed in 1951. KNN algorithms have limitations when it comes to information retrieval.
Here are the key limitations:
- Scalability: KNN algorithms don’t scale well with large datasets. As the dataset grows, the algorithm becomes increasingly inefficient and time-consuming. This can impact the overall performance of the model and make it impractical for handling big data.
- Curse of dimensionality: KNN algorithms struggle with high-dimensional data. As the number of dimensions increases, the algorithm’s performance deteriorates. This is known as the curse of dimensionality. It becomes challenging for KNN to find meaningful patterns or similarities in high-dimensional spaces, leading to less accurate results.
- Memory and storage requirements: KNN algorithms require storing the entire training dataset in memory. This can be memory-intensive and costly, especially for large datasets. Additionally, as new data is added, the algorithm needs to update and maintain the entire dataset, which can be resource-intensive.
- Sensitivity to noise and outliers: Outliers can significantly impact the algorithm’s decision-making process, leading to inaccurate results. Noise in the data can also introduce errors and affect the algorithm’s performance.
- Determining the optimal value of K: The choice of the value for K, the number of nearest neighbors to consider, is crucial in KNN algorithms. Selecting an inappropriate value for K can lead to overfitting or underfitting the data. Finding the optimal value of K requires careful experimentation and tuning.
- Imbalanced data: KNN algorithms struggle with imbalanced datasets where the number of instances in different classes is significantly different. The algorithm tends to favor the majority class, leading to biased predictions and poor performance on minority classes.
Another proximity-based algorithm emerged to offset the drawbacks of KNN — Approximate-Nearest Neighbors (ANN). ANN can reduce computational time and better handle large datasets than KNN. However, there are also some downsides to using ANN. These include potential approximation errors due to sacrificing accuracy for efficiency, as well as the sensitivity of the algorithm to various parameters, which may require careful tuning for optimal performance.
It’s important to consider these limitations when using KNN and ANN algorithms for information retrieval tasks. Given the complexity of enterprise datasets, alternative algorithms or techniques are more suitable for achieving accurate and efficient information retrieval.
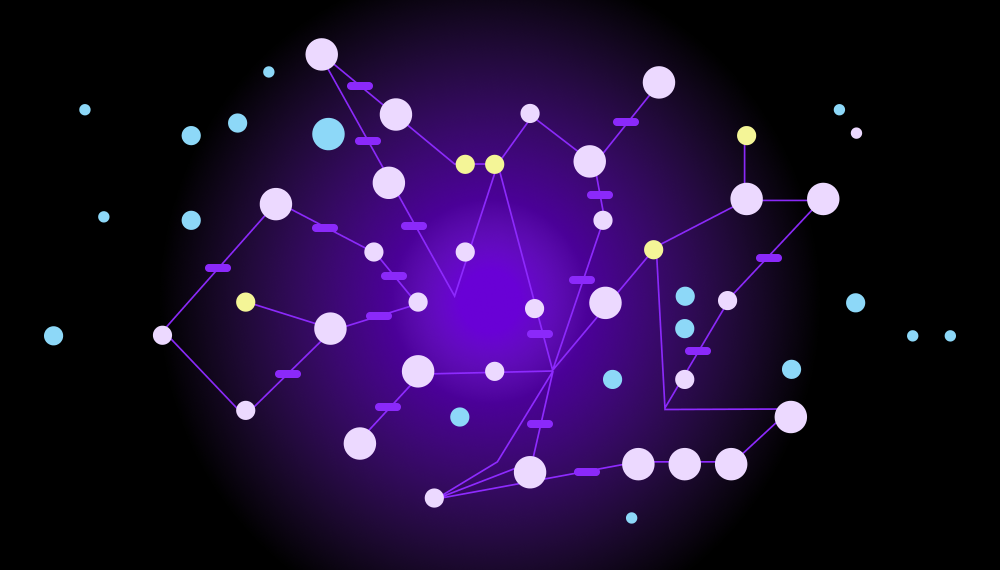
Dense and sparse mapping
Enterprise data often presents challenges for vector retrieval due to dense and sparse mapping. For example, when dealing with user manuals for different versions of a device, the device name may appear frequently, leading to dense mapping. This can lead to inaccurate vector estimates, leading to incorrect results or an inability to accurately retrieve relevant information. Additionally, dense mapping can be computationally intensive and time-consuming, leading to slow retrieval times.
On the other hand, numerical data like tables and code can be interpreted as similar when compared with other data objects like text. Numerical data gets grouped together, leading to sparse mapping.

In the above sparse mapping example, the “Q” represents a natural language question and the numbers represent numerical data. It’s hard for the system to retrieve accurate information because it can only go off of distance between vectors and has no context on the actual relationship between the number-based data and the text-based question. Thus, the system casts a wide net and brings back irrelevant information in the process.
Cost and rigidity
Vector databases are costly and onerous to maintain. Every time you need to add new data, it can’t just append it to the existing data set. It needs to rerun all the data and assign each data object a new value. This is because what is in the entire dataset determines what value is given to each vector embedding. With new data added every day, an enterprise environment demands a more dynamic, flexible, and affordable solution.
Garbage in, garbage out
The level of hallucination, or the accuracy of the answers, in a language model is dependent on the quality of training data and the training techniques you apply. If the data sent via vector-retrieval to the LLM is incorrect (for the reasons discussed above), then the output from the LLM will be poor. For this reason, vector-based retrieval may not be the best option for enterprise use, as it isn’t always able to provide reliable and accurate results.
Graph-based RAG: a better approach for enterprise data
To overcome the limitations of vector retrieval, WRITER has developed a one-of-a-kind graph-based RAG approach that proves to be superior in accuracy and handling enterprise data. This approach, called the WRITER Knowledge Graph, uses a specialized LLM trained to process data at scale and build valuable semantic relationships between data points.
Like any RAG process, the WRITER Knowledge Graph follows the three steps of data processing, query and retrieval, and answer generation:
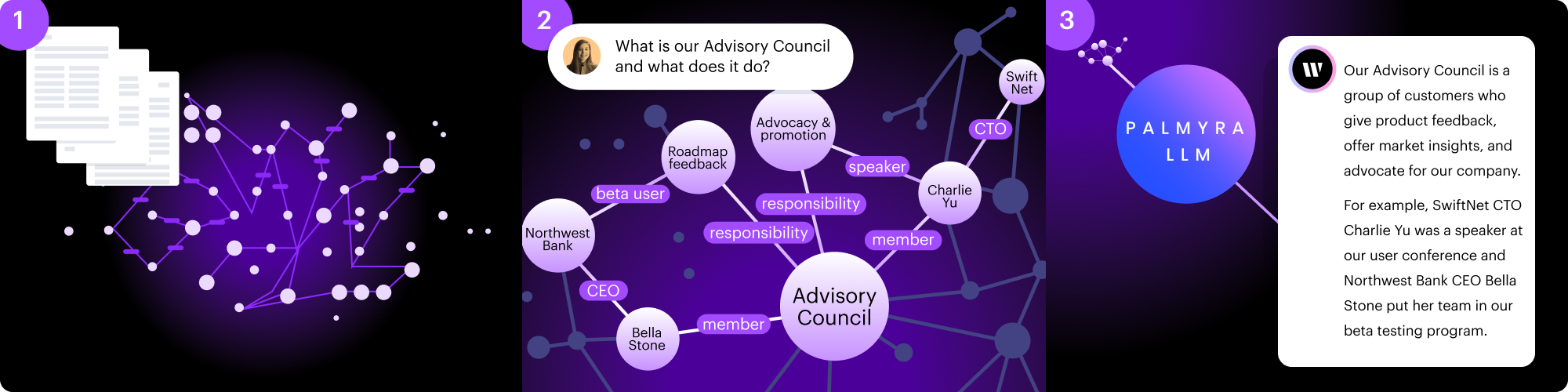
1. Data processing
Entities are represented as nodes, and relationships are represented as edges. The edges can be used to show how the nodes are related. For example, a graph of a customer database could include a node for each customer, and edges to represent their purchases.
2. Query and retrieval
Graph-based retrieval uses a combination of natural language processing (NLP) algorithms, heuristic algorithms, and machine learning techniques to understand the context of the query and identify the most relevant entities and relationships.
3. Answer generation
The LLM then takes those relevant data points and formulates an answer.
By storing data in a cost-effective and easily updatable graph structure, semantic relationships are retained, resulting in accurate retrieval of relevant data for each query. Advanced retrieval techniques and LLM enhancements can further improve accuracy and reduce hallucinations.
Supports your file types: Knowledge Graph handles structured and unstructured data, including docs, spreadsheets, charts, presentations, PDFs, audio and video files, and more.
Processes dense data: Where vector-based RAG breaks down when data is highly concentrated, Knowledge Graph excels at retrieval with dense data.
Updates data efficiently: Unlike vector-based RAG, adding or updating data to Knowledge Graph is easy, fast, and inexpensive.
Discover the full potential of enterprise RAG with WRITER Knowledge Graph
While vector retrieval has its merits, it’s important to understand its limitations when considering its use in enterprise applications. The power of accurate knowledge retrieval lies in adopting a graph-based RAG approach, which leverages specialized LLMs and semantic relationships to provide superior results. By choosing the right retrieval techniques and enhancing LLM capabilities, enterprises can realize the full potential of generative AI for their internal knowledge and data.
To learn more about implementing a robust knowledge retrieval system, visit our Knowledge Graph product page.