Innovation
– 9 min read
Making sense of AI foundation models
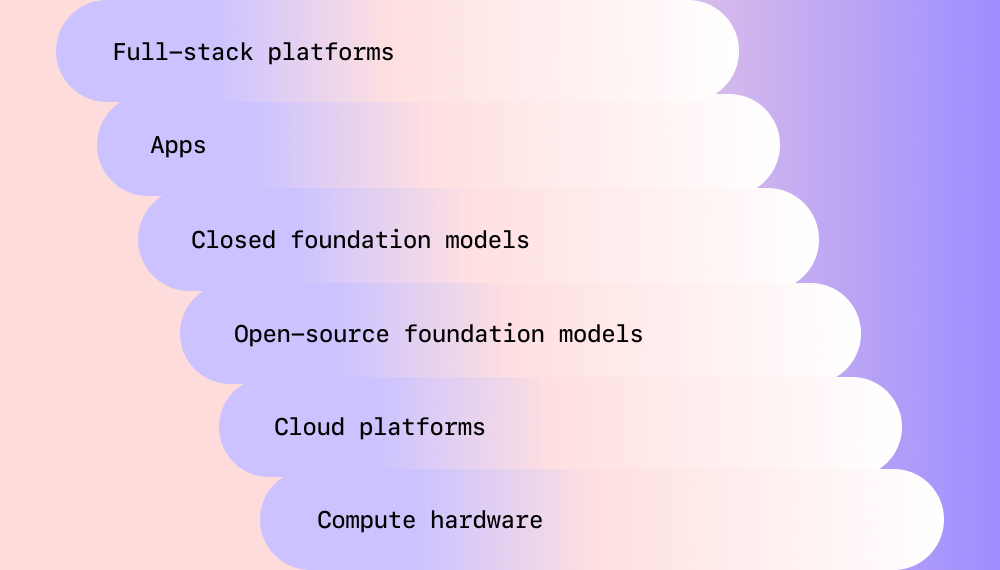
Foundation models are the backbone of generative artificial intelligence (AI) applications that have leaped into public awareness over the past year. Most people see foundation models in action as they power easy-to-use generative AI products like the WRITER platform, ChatGPT, and Midjourney.
But here’s something you may not know: many foundation models are available through open-source communities like Hugging Face. Still others can be self-hosted for businesses to build, train, customize, and embed generative AI throughout their organizations and their products.
However, foundation models come with their limitations. That’s why it’s essential for businesses that are serious about using AI at scale to understand them.
Let’s delve deeper into what AI foundation models are, how companies can implement them in their operations, the shortcomings associated with them, as well as the latest breakthroughs in foundation models that help tackle these potential issues.
- AI foundation models are pre-trained models that can perform general tasks, trained on large datasets, which businesses can fine-tune on narrower datasets for specific tasks
- Companies can use foundation models for automation, content generation, data analysis, translation, and personalization
- Examples of foundation models include GPT, Palmyra, and DALL-E
- Limitations of foundation models include the need for further training, privacy and security concerns, black-box decision-making, and biased or false information
- Palmyra LLMs are a set of generative foundation models built by WRITER to help companies scale their usage of WRITER and build AI into their products

What are AI foundation models?
Foundation models are AI models that are trained on massive datasets to perform general tasks. You can fine-tune them on narrower data sets to perform specific tasks in your applications.
Imagine you wanted to create an application that writes release notes for your product. You take a foundation model that can already understand and generate text. Then, you teach it how to do the specific release note-writing task.
The training data would include:
- Release note examples, so the model knows what the desired output should look like
- Domain-specific data (information about your product or industry), so the model can learn relevant terminology
You could also train the model further on voice examples so it learns how to write in your unique style.
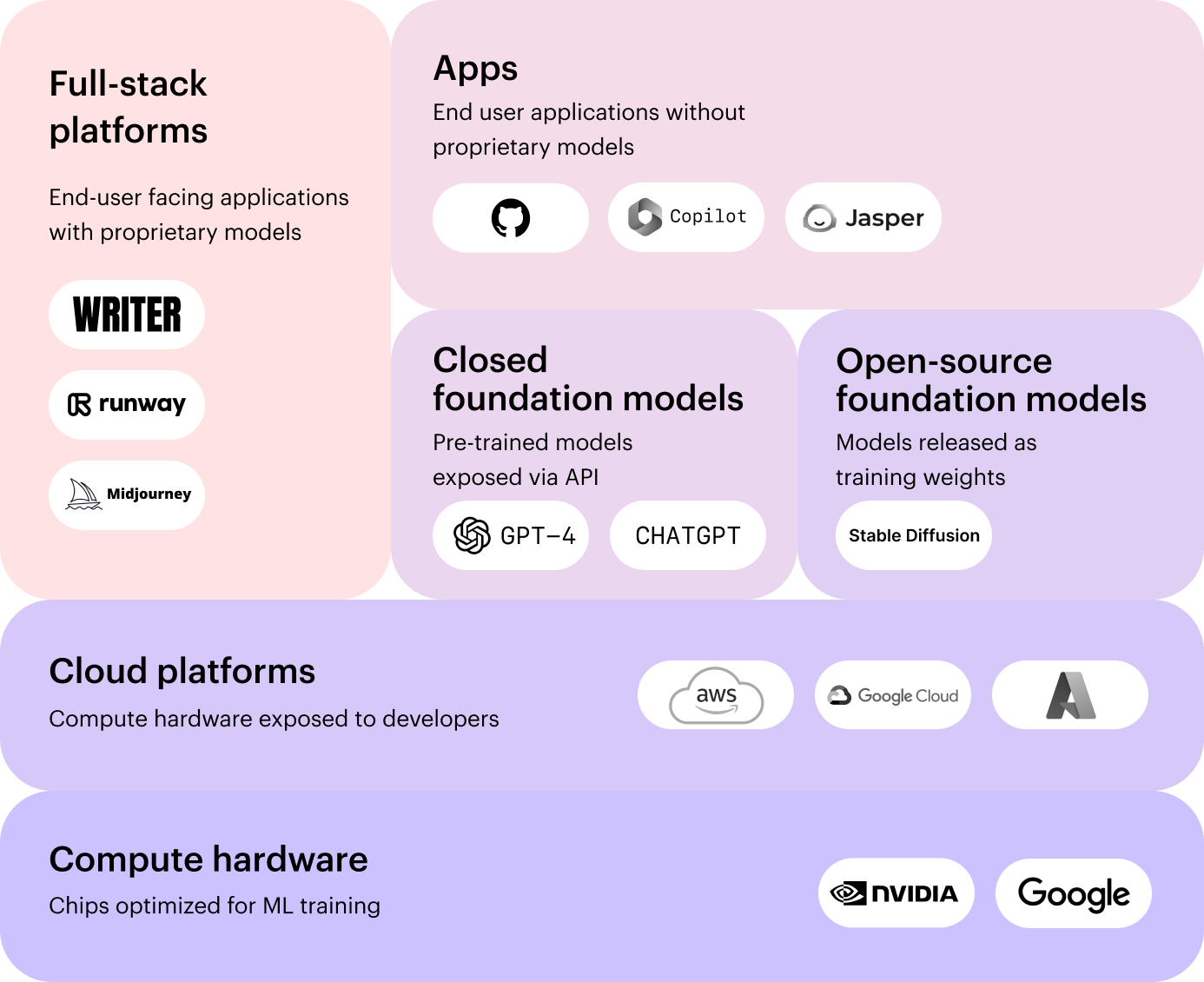
Are foundation models and large language models the same thing?
Foundation models refer to an umbrella category of AI models, of which large language models (LLMs) are one type. LLMs are trained on text data to understand and generate human language, enabling tasks such as translation and text generation.
Other types of foundation models include:
- Image models, that analyze and interpret visual content like images or videos for tasks like image classification and object detection.
- Audio models, which generate music, sounds, and speech from text prompts
- Multimodal models, that combine information from multiple modalities (text, images, audio) to understand and generate content that incorporates different types of data. They’re used for tasks like image captioning, audio editing, and video understanding.
Within the category of LLMs, there are two different types of architectures: Generative Pre-trained (GPT) and Bidirectional Transformer (BERT). GPT is geared towards generating new text, while BERT is designed for understanding and extracting meaning from text.
Generative Pre-trained (GPT) architecture
GPT is a type of language model that’s been pre-trained on a large amount of text data, like books, articles, and websites. It learns patterns, grammar, and context from this training data. Once trained, it can generate new text by predicting the next word or words based on the context it has learned. It’s like a virtual writer that can create coherent and meaningful sentences and paragraphs.
Bidirectional Encoder Representations from Transformers (BERT) architecture
BERT is another type of language model that’s designed to understand the meaning and relationships between words in a sentence. It uses a technique called “bidirectional” training, which means it looks at the words before and after each word in a sentence. By considering the full context, BERT can better grasp the meaning and nuances of the sentence. It’s like a language detective that analyzes the whole sentence to understand what it’s about and how different words relate to each other.
Understanding AI foundation models in practice
AI foundation models have exploded in recent years. The models are what ultimately allow businesses to automate various processes, reducing costs and making operations more efficient.
Once they’ve been fine-tuned, AI foundation models can help companies with things like:
- Content generation, both written and visual
- Translation, improving the accuracy and speed of translations
- Personalization, by generating content or recommendations tailored to each customer
Organizations can also use foundation models to develop virtual assistants. ChatGPT probably springs to mind. But a virtual assistant might also look like a chatbot that answers customer questions as they navigate your site.
Though you might not have heard of some foundation models, you’ll likely recognize the applications that build on them.
Palmyra, the set of LLMs behind WRITER
Palmyra, the WRITER-built family of LLMs, is the backbone of the WRITER generative AI platform. While Palmyra LLMs work as-is for many business use cases, enterprise customers can work with WRITER solutions architects to further fine-tune the models for industry or company-specific use cases. The open and transparent Palmyra LLMs are top-scoring on key benchmarks, faster and more cost-effective than larger models, fine-tuned for specific industries, and able to be self-hosted.
Smaller Palmyra LLMs are foundation models available open-source through Hugging Face. Startups and tech partners can take open-source models and further customize them with fine-tuning to build bespoke AI applications.
GPT-n, the series of large language foundation models behind ChatGPT
The GPT-n series is the set of large language foundation models that OpenAI built ChatGPT on. GPT-n are deep learning-based language models that use unsupervised learning to generate human-like text. The models generate natural language based on a large corpus of text. The GPT-3 model, alongside GPT-3.5 and GPT-4, allows ChatGPT to generate natural language conversations.
DALL-E, the visual foundation model behind Canva ‘magic’
DALL-E (short for “Deep Artificial Language Learning Engine”) is a visual foundation model developed by OpenAI for image generation based on text descriptions. OpenAI trained DALL-E on a huge collection of images and text descriptions, allowing it to generate novel text-to-image creations that capture the meaning of the given description.
Canva recently released a set of ‘magic’ AI features on their platform, allowing users to quickly create a custom image based on a text description. DALL-E is one of the foundation models Canva based its features on.
Limitations of foundation models
Foundation models are powerful tools for businesses and organizations, but they have some important limitations.
Challenging to deploy
Foundation models are typically very large, with millions or even billions of parameters. The size of these models can result in long inference times, making them slow compared to smaller models. Additionally, the memory requirements of foundation models can be substantial, making them challenging to deploy.
In comparison to some of the other large language models, such as GPT-4, Palmyra LLMs are much smaller, with a maximum of 43 billion parameters compared to GPT-4’s, reportedly 1.8 trillion. Palmyra LLMs are faster, more efficient, and cheaper to use without compromising performance for complex tasks, achieving top scores on key benchmarks like Stanford HELM .
Further training
One of the biggest challenges is that foundation models must be fine-tuned for specific tasks to achieve the best results. The training process can be tricky and expensive. Plus, if you don’t fine-tune models on high-quality data, you risk the ‘garbage in, garbage out‘ effect.
Privacy and security
Another limitation is that most foundation models require user inputs to train. The process of training the model on information relevant to your company might mean sharing sensitive data. If the organizations who provide the foundation models store your proprietary data, that poses a significant risk to your privacy and security.
WRITER provides the highest levels of security and privacy protection, so you can rest assured that your data is safe as we fine-tune our models to write in your company voice. WRITER adheres to SOC 2 Type II, PCI, HIPAA, GDPR, and CCPA.
Black box decision making
Black box decision-making is when the AI model makes decisions without providing enough insight into how it came to a decision. A lack of transparency in decisions can be a major problem for businesses because when people don’t know the reasoning behind a decision, it’s harder to verify the accuracy or trustworthiness of the model. Additionally, it can be difficult to explain these decisions to stakeholders, which can create a lack of trust and confidence in the AI model.
In contrast, WRITER LLMs are transparent and auditable. With WRITER, customers can inspect the code, data, and model weights used to make decisions.
Biased and false information
Foundation models may produce biased or false information for various reasons, such as outdated data or algorithms, biased data sets, or the lack of consideration of external factors. Inaccurate content can cause confusion, miscommunication, and even harm or misinformation, resulting in distrust between the creator and the reader.
Automated decision-making systems based on foundation models can lead to biased decisions, as they may not factor in nuances or exceptions in individual cases. Additionally, if a business relies on an AI model to make decisions, and the model is biased or contains false information, the business could make decisions based on incorrect data, leading to damaging consequences.
WRITER connects to your business data so it can reflect company facts in its output. Knowledge Graph, your company’s information layer, enables the LLM to retrieve data from important sources like wikis, cloud storage, databases, and more, which helps prevent the models from ‘hallucinating‘ and generating false information.
The Knowledge Graph checks generated content against the customer’s own content, automatically detecting and highlighting any text that needs to be reviewed.
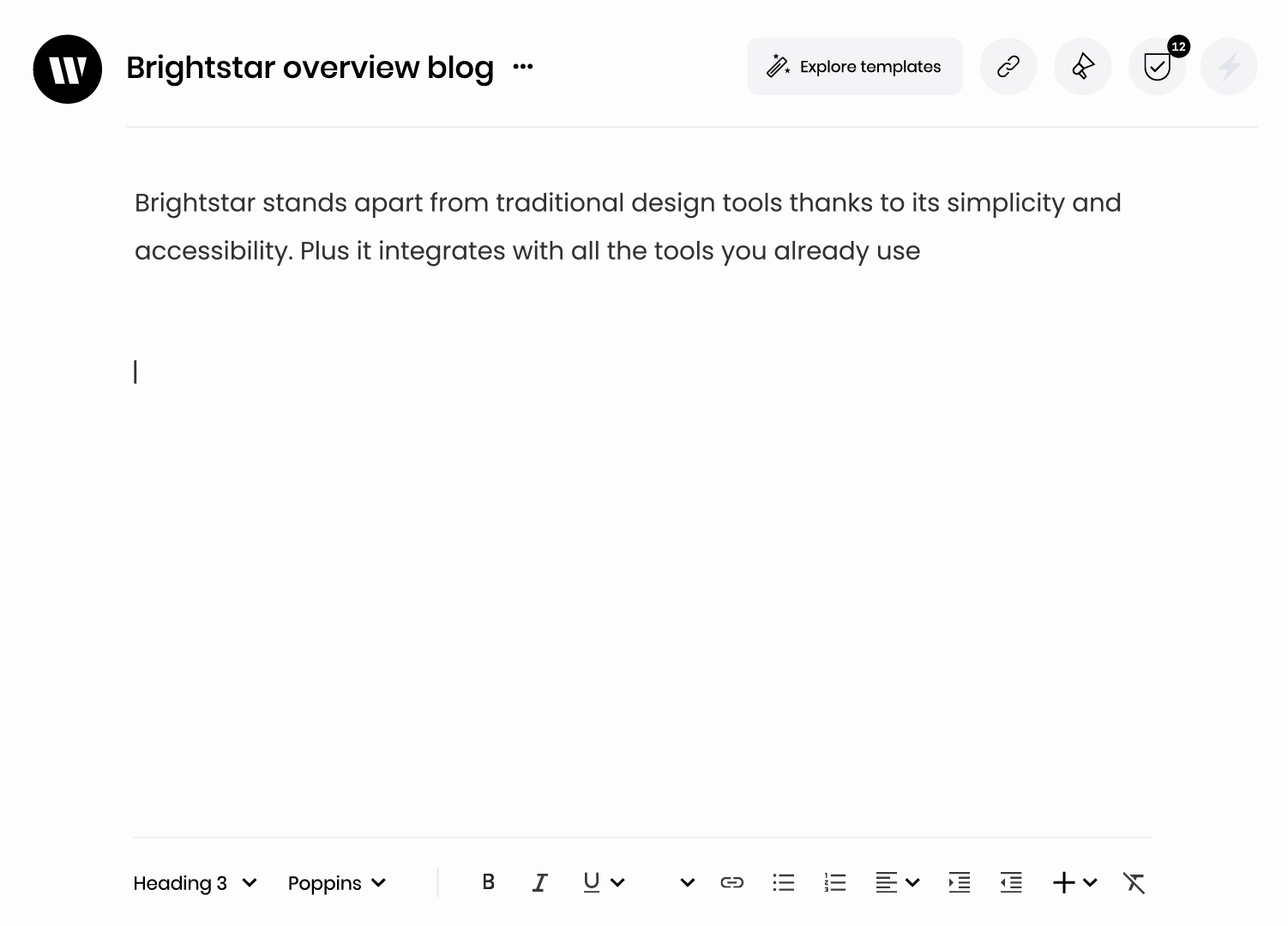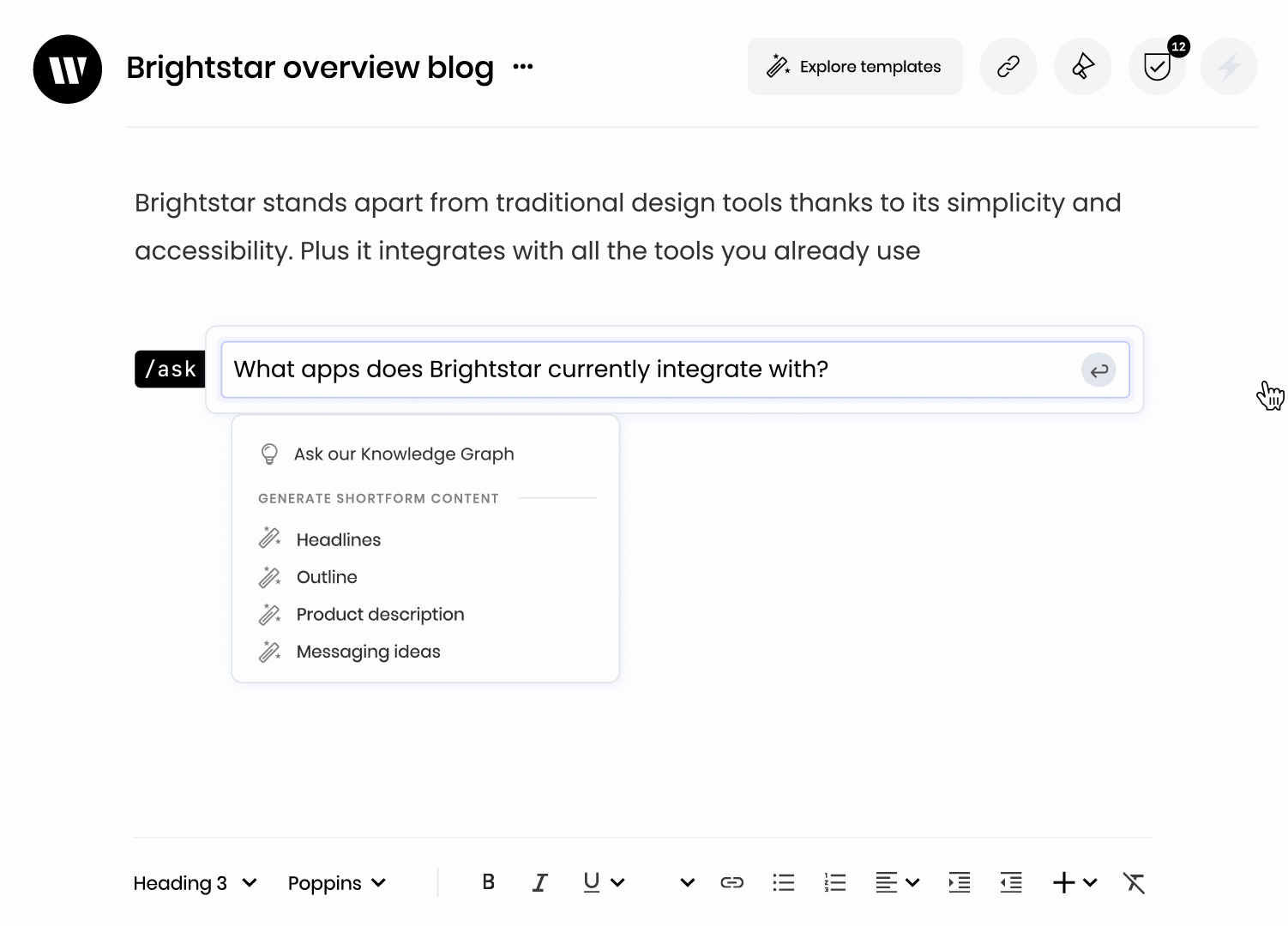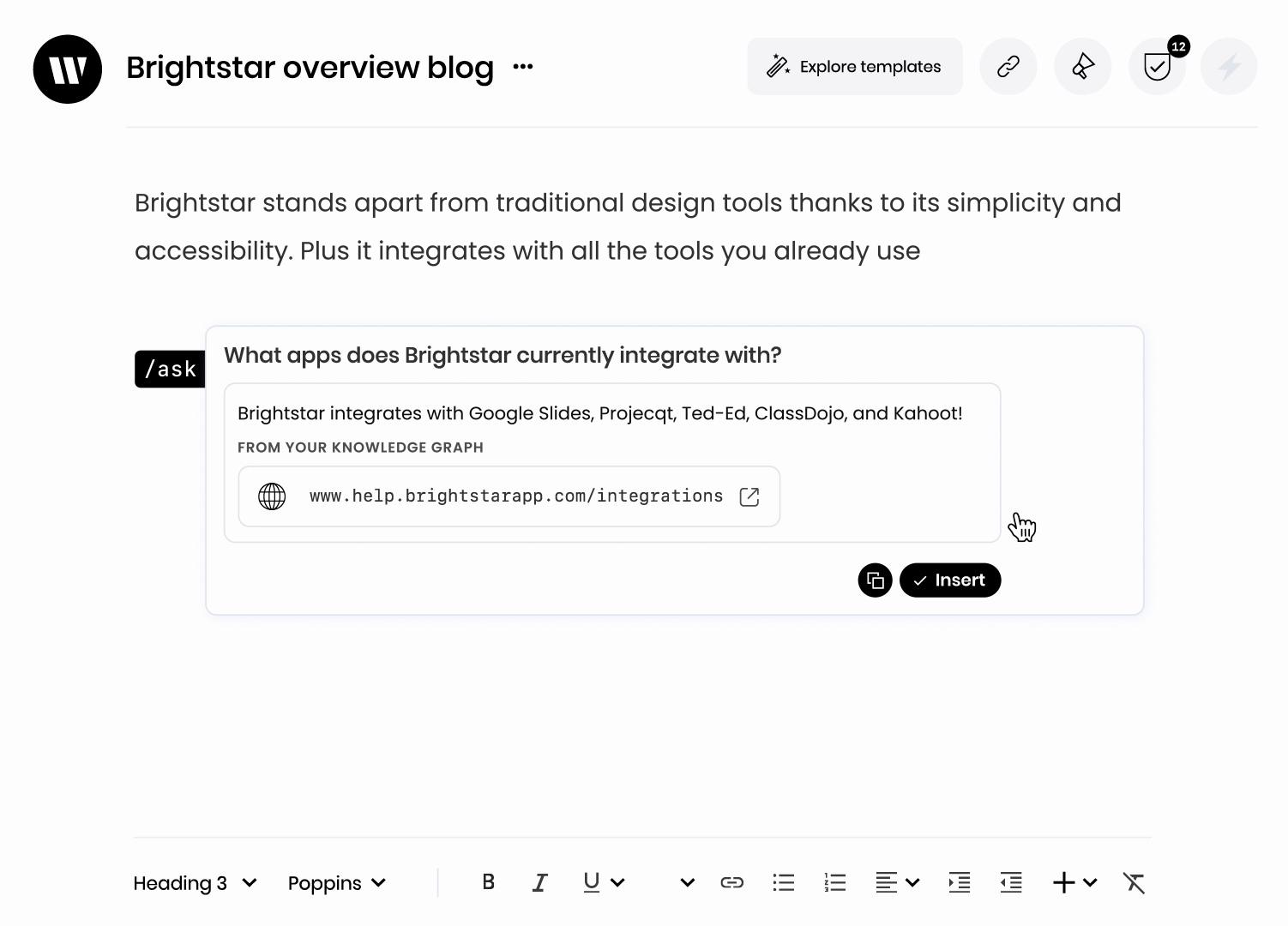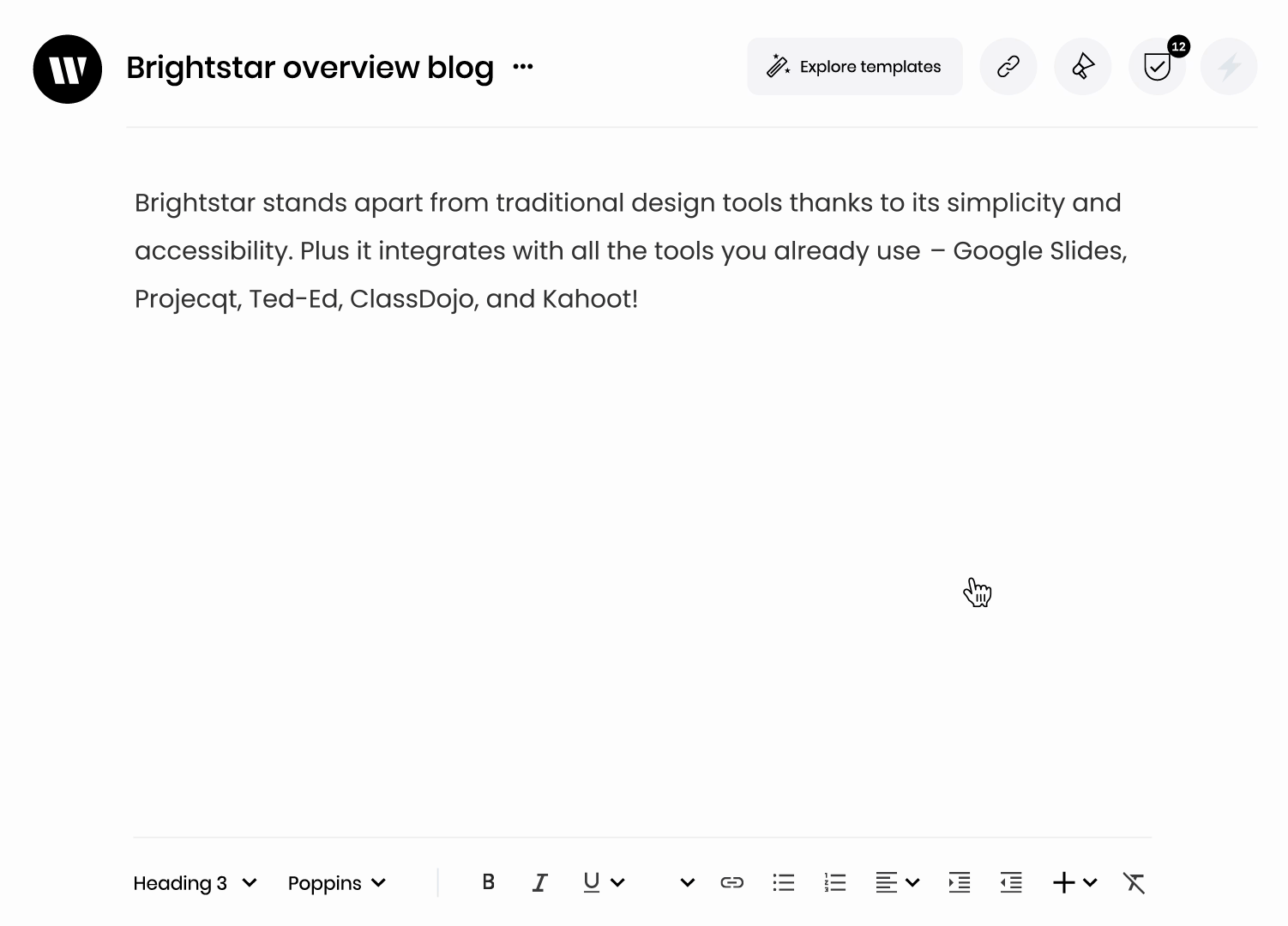
Specialized AI foundation models
At WRITER, we’ve developed a set of generative AI foundation models specifically geared toward enterprise use cases.
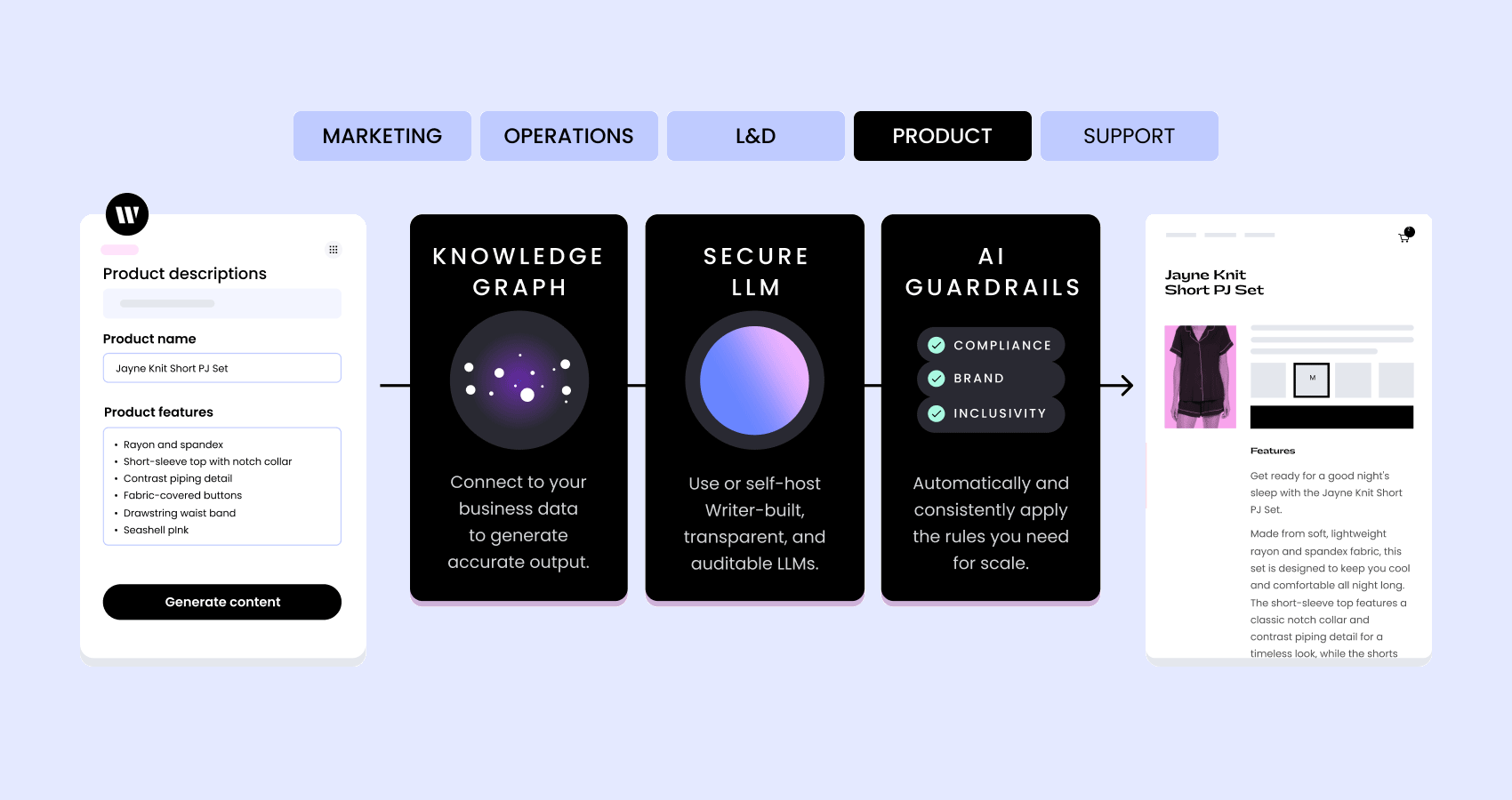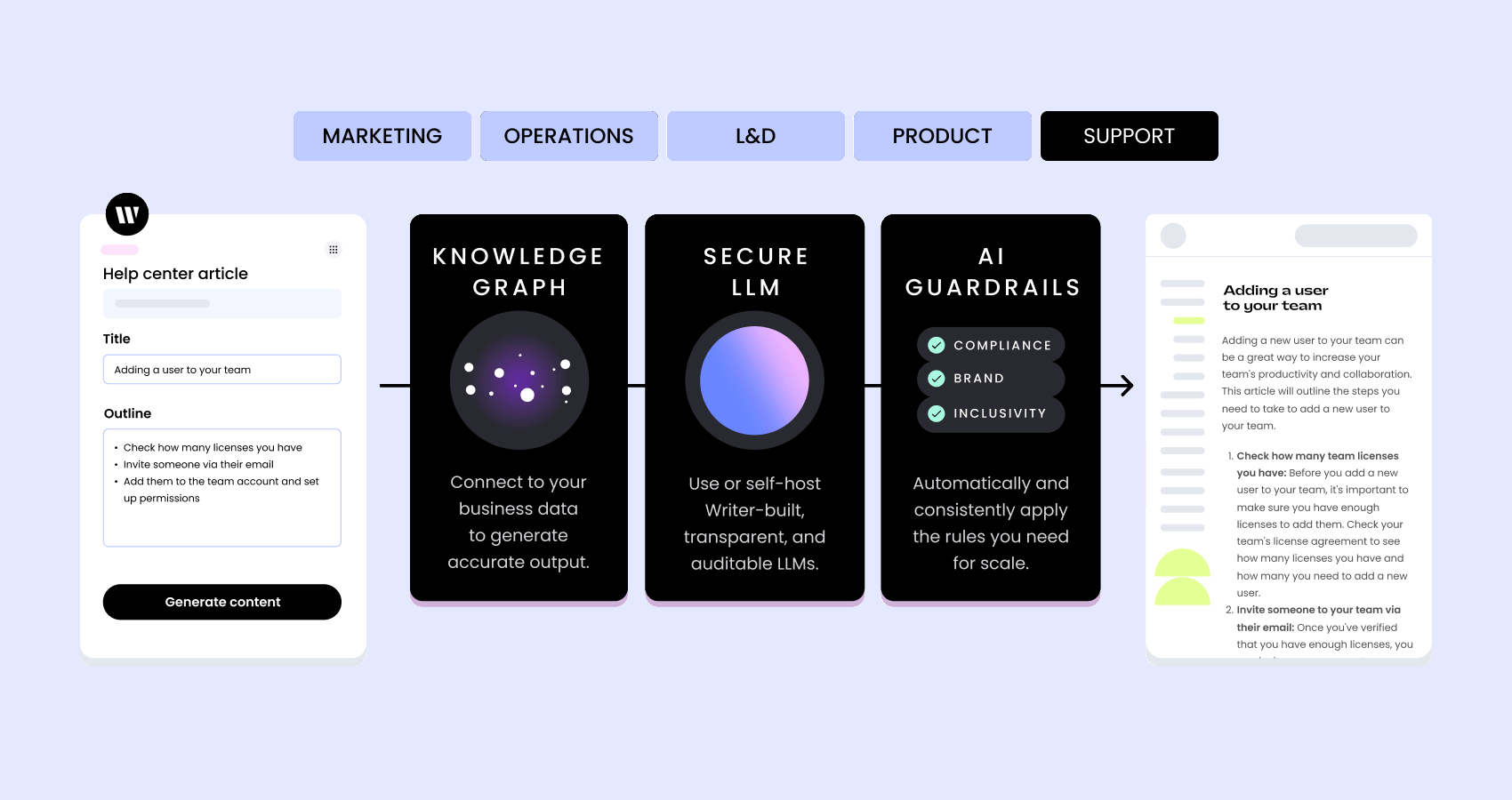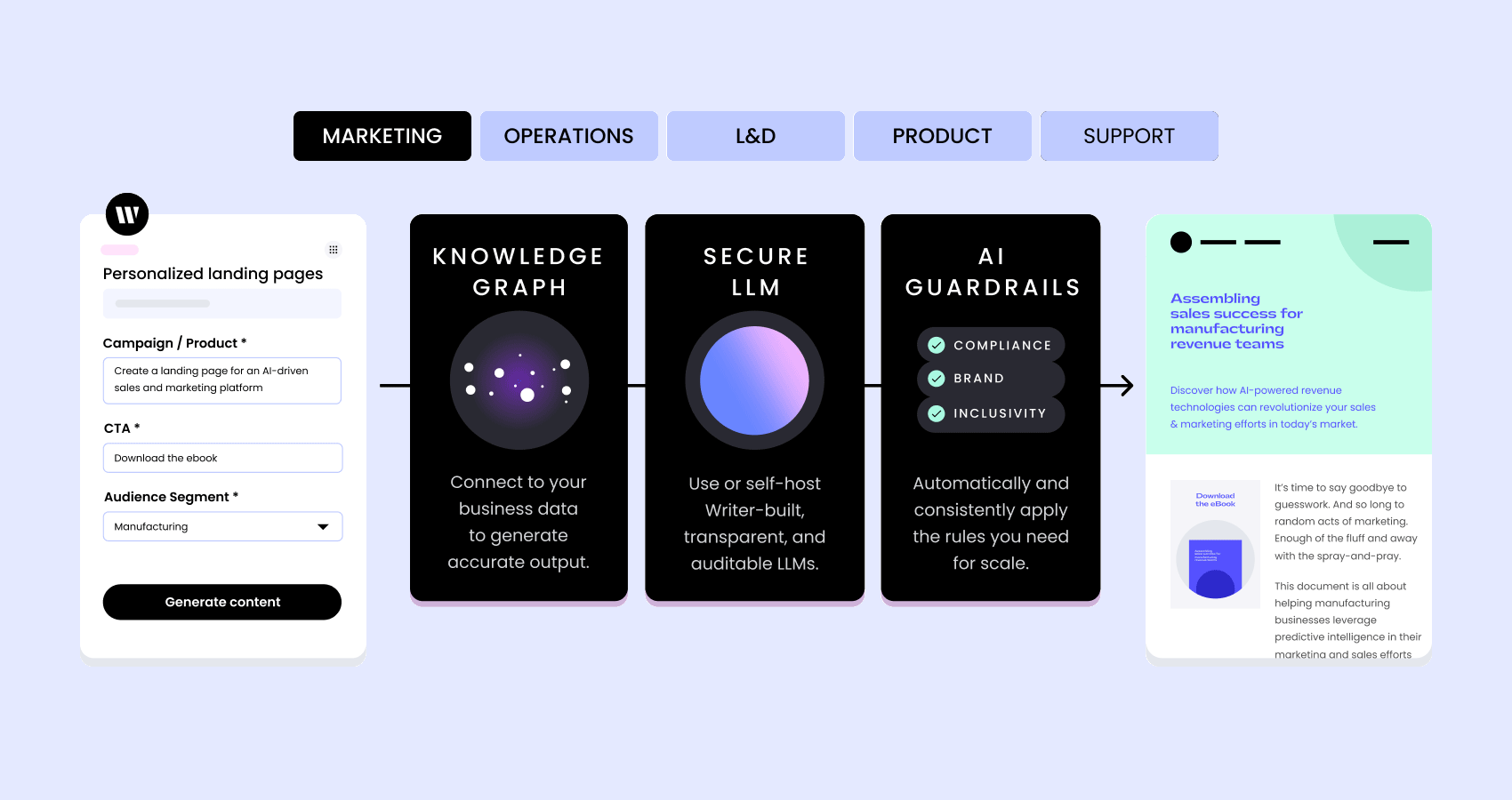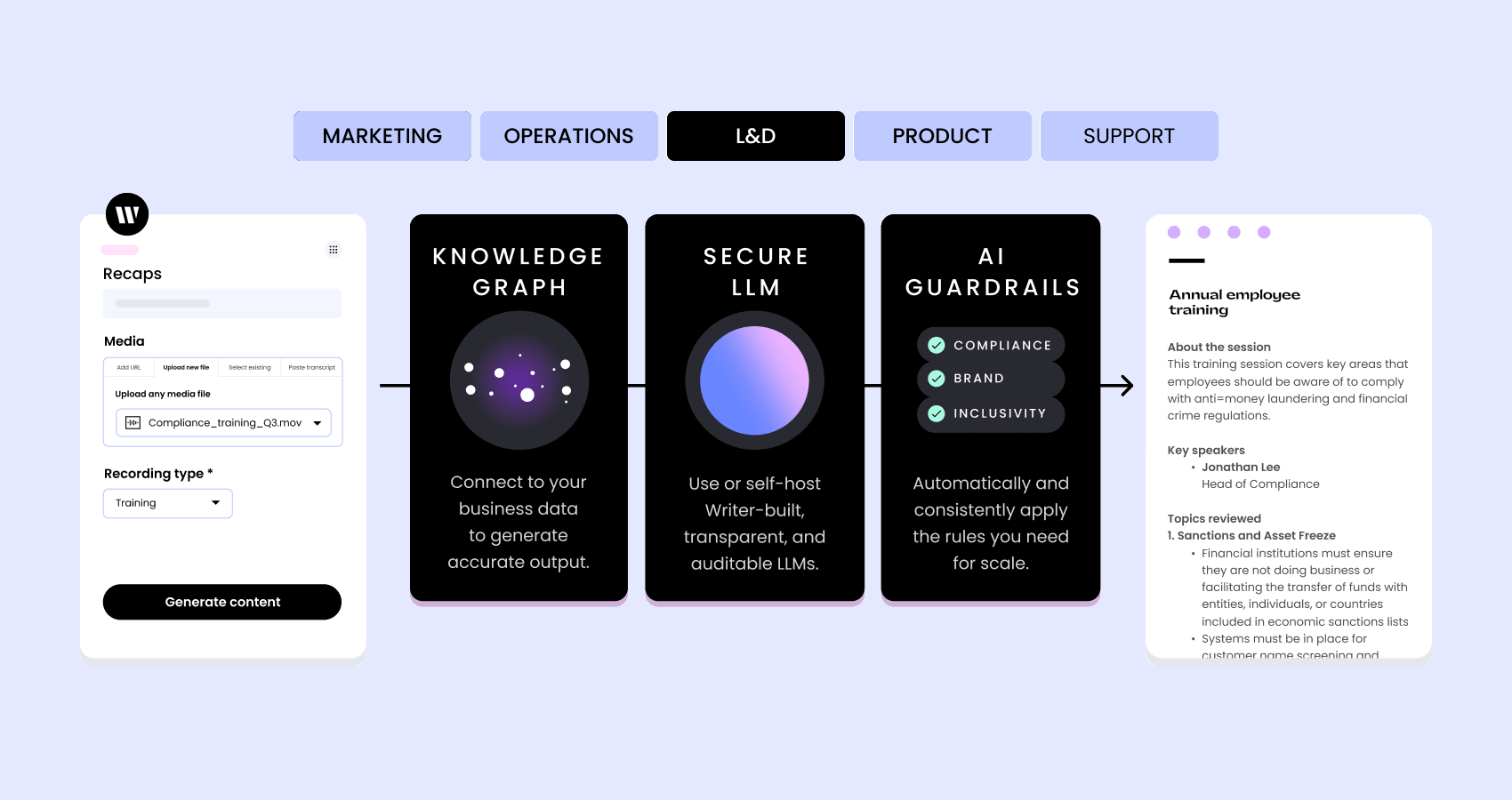
Unlike other general-purpose models for language generation, we pre-train Palmyra LLMs on a curated set of business and marketing data and fine-tune them for specific industries like healthcare and financial services. We combine these powerful LLMs with Knowledge Graph and an application layer of prebuilt and composable UI options to enable enterprises to embed generative AI into any business process. Learn more.
More resources

AI in action
– 7 min read
[Unpublished] Generative AI in plain language: what it is, what’s hype, and what’s real
Alaura Weaver

