Thought leadership
– 10 min read
The three keys to escaping AI POC purgatory
Techniques for enterprise AI engineers

Sam Julien | November 26, 2024

Accuracy, efficiency, and user adoption make it challenging for AI applications to move from development to production. Enterprise AI engineers can escape AI POC purgatory by focusing on scalable tasks and emphasizing the importance of repeatable accuracy and good UI/UX practices. A full-stack approach — such as the adoption of a “microservices mindset” and advanced tooling — simplifies integration and boosts efficiency in AI deployments. Check out our webinar on the topic for more insights.
While development use cases for AI are on the rise, production implementations are dwindling. This trend — driven by challenges such as low accuracy, efficiency, and adoption — threatens to trap businesses in a cycle of proof-of-concept (POC) purgatory. To overcome this, we’re taking enterprise AI engineers through a three-step framework for overcoming key challenges using a full-stack approach to generative AI.

Understanding the challenges
There’s a lot of skepticism around AI right now following a big breakthrough year in 2023. Many headlines talk about the AI gold rush being a failure, deflating projects, and that we’re heading for AI winter. Between October 2023 and February 2024, there was a noticeable uptick in AI development projects across nearly every industry. But during these same periods, there was also a decline in the number of projects advancing to production.
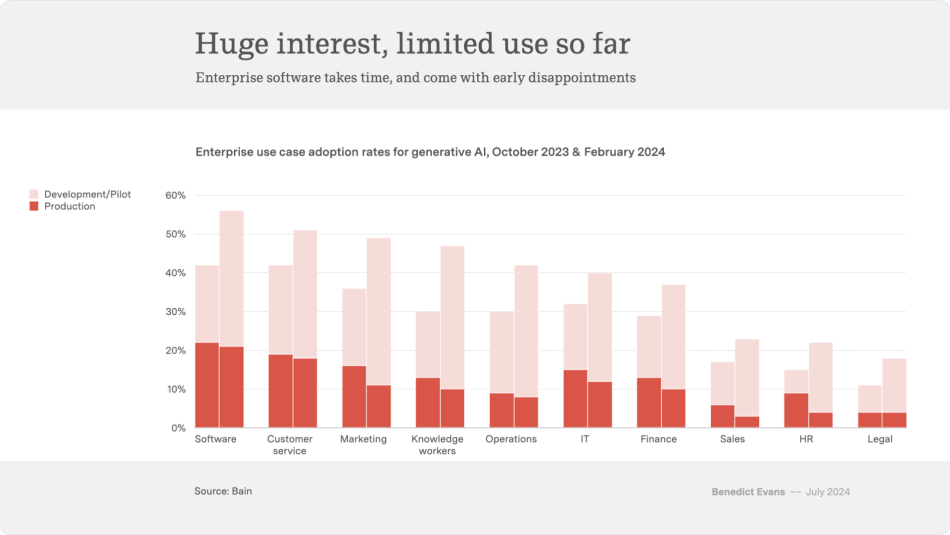
This pattern highlights the “gravity well” we’re seeing AI become for enterprises. Organizations are putting together proofs of concept (POC) and demo projects, but they’re remaining stuck in a cycle of extensive development without achieving production outcomes. The conversation is shifting from excitement to how enterprises can achieve real value — but the issues of low accuracy, low efficiency, and low adoption are hindering this progress.
To overcome these issues, use these three techniques:
- Reconcile AI engineering scope with a full-stack approach
- Aim for repeatable accuracy at each layer of the stack
- Scale UI/UX quickly with best practices and advanced tooling
Let’s look at each of these.
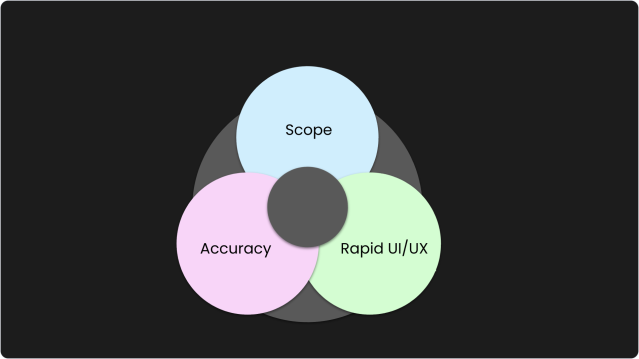
1. Reconciling AI engineering scope
The enterprise is suffering from an AI paradox: There’s a need for substantial infrastructure and resources to support AI engineering, but immediate ROI comes from targeted, scalable tasks. Enterprises often begin their AI journey with simple, single-purpose SaaS solutions that are easy to implement. As organizations build up more and more, security risks and management complexity also increase.
Needs typically evolve towards more complex scenarios requiring higher accuracy, so organizations transition to developing custom AI solutions. This shift to DIY requires significant investment in building AI infrastructure and teams — managing everything from data pipelines to app hosting. An investment like this pressures enterprises to deliver results, often leading them to tackle overly ambitious projects.
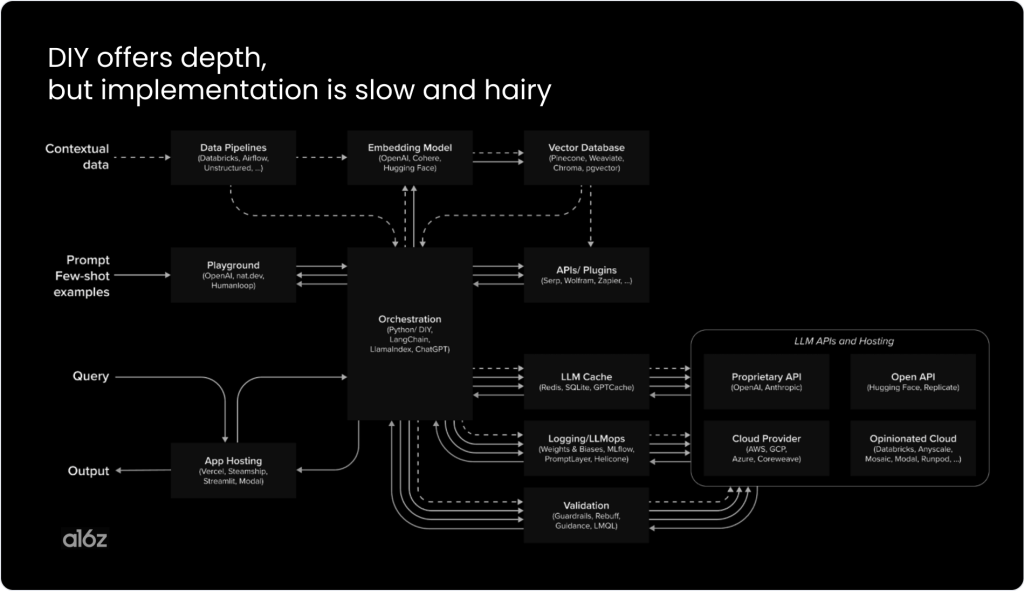
We’ve seen a lot of enterprise teams attempt to tackle every organizational issue with AI, or try to “boil the ocean.” Despite significant investments in AI infrastructure and resources, these teams struggle to effectively deploy AI across all intended applications. Rather than doing this, we recommend enterprises to think in microservices and adopt a full-stack approach.
Think microservices, not monoliths
Adopting a microservices approach rather than building monolithic systems is key to effectively managing the scope of AI engineering. This strategy focuses on developing small, specialized applications that address specific tasks in each function — making them easier to manage and scale. Each microservice operates independently but can be orchestrated together with others to form a comprehensive solution. This not only saves time and money but also improves ROI by allowing for incremental improvements and focused solutions.

Aim for a full-stack approach
An enterprise-grade, full-stack generative AI platform requires five things:
- A way to generate language (i.e., a large language model)
- A way to supply business data
- A way to apply AI guardrails
- An interface you can easily use
- The ability to ensure security, privacy, and governance for all of it
For example, at WRITER, we integrate foundational technologies like LLMs, retrieval-augmented generation (RAG), and guardrails. All of this is supported by a sophisticated inference and infrastructure platform. Then, there’s prebuilt applications as well as Writer AI Studio. AI Studio is our suite of development tools, including no-code options, Python development framework, and APIs that makes it easy for anyone to build and deploy AI apps and workflows.

The software engineering lifecycle is “make it work, make it right, make it fast.” Shawn Wang says the AI engineering lifecycle is more like “make it work on one thing you want, make it work on most user queries, and make it efficient.”
I think you can extrapolate that into an enterprise context and say “make it work for one use case, generalize it to other use cases or verticals, and then make it efficient for other teams to build.”
2. Aiming for repeatable accuracy
Because LLMs are inherently non-deterministic, they don’t consistently produce the same output for the same input — similar to the unpredictability of dice rolls. This presents challenges for enterprises that require dependable and repeatable accuracy in their AI applications. Another issue is that enterprise data is typically dense and specialized, making it difficult for the algorithm to parse and rank according to what’s most contextually relevant.
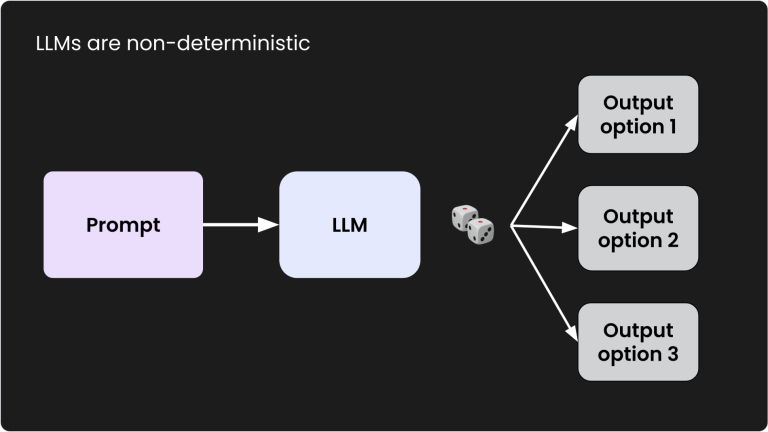
There’s three different layers where you can employ a couple of techniques to start improving the accuracy of your AI engineering projects.
Prompt and code layer
In addition to taking advantage of strategies for prompting, tool calling, sometimes referred to as function calling, enables LLMs to access specific functions that improve accuracy by allowing interaction with external APIs and performing actions. Our latest model, Palmyra X4, incorporates this feature.
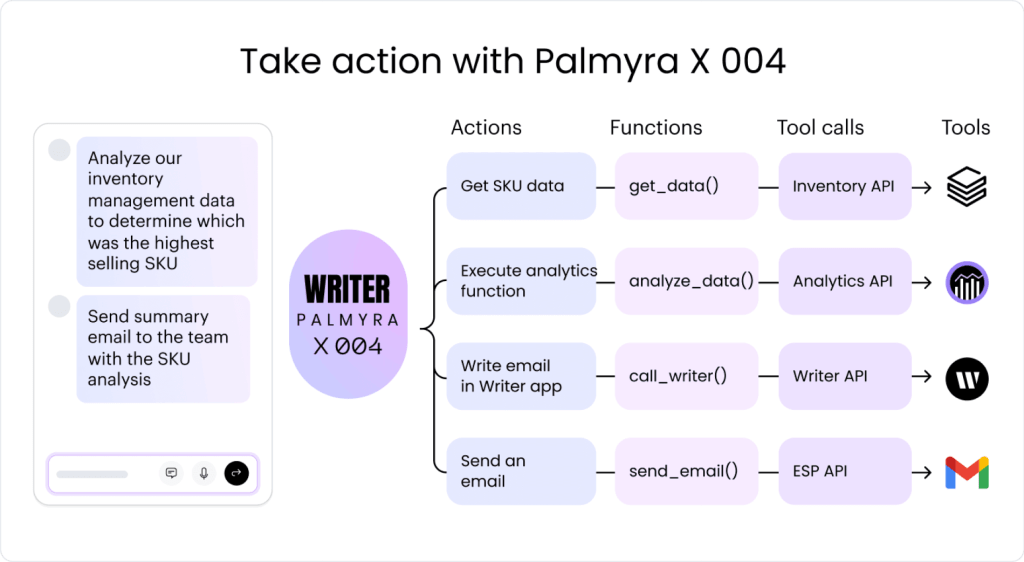
Developers define these functions in their code and describe them using a JSON schema — which includes details on their purpose and parameters. This schema is integrated into the LLM’s toolkit, allowing it to recognize and execute these functions as needed, which improves output quality and expanding capabilities.
tools = [
{
"type": "function",
"function": {
"name": "get_product_info",
"description": "Get information about a product by its id",
"parameters": {
"type": "object",
"properties": {
"product id": {
"type": "number",
"description": "The unique identifier of the product to retrieve information for",
}
},
"required": ["product_id"],
},
},
}
]messages = [{"role": "user", "content": "what is the name of product with id 1234?"}]
response = client.chat.chat (
model="palmyra-X4", messages=messages, tools=tools, tool_choice="auto"RAG layer
At the RAG layer, graph-based RAG has been a hot topic this year, something WRITER has been doing for several years. The graph structure effectively preserves data relationships — enhancing accuracy and reducing hallucinations. We don’t stop there though, we combine graph-based RAG with other techniques like compression to maintain context and advanced methods like fusion-in-decoder to minimize hallucinations. This blended approach has given us over 86% accuracy with less than 3% hallucinations. When benchmarked against traditional methods, our approach comes out on top, so we urge you to combine multiple techniques in your RAG, especially with graph-based RAG.
LLM layer
At WRITER, we’re passionate about using domain-specific LLMs, where you train models on industry-specific data. This allows you to maintain more control over sensitive information, reduce computational demands, and accelerate AI deployment. We recently introduced two new models — Palmyra Medical and Palmyra Finance, available on Hugging Face with an open model license as well as in AI Studio and our API. Compared to some general-purpose models, we found them to be 40% more accurate, take 50% less time to deploy, and 35% cheaper to run.

We’ve also developed a technique called “Writing in the Margins,” an inference pattern that improves LLMs’ ability to process long prompts by segmenting input sequences into smaller units. Writing in the Margins helps improve accuracy with longer context when you’re dealing with LLM and RAG approaches. Read our research paper to learn more about this technique.
3. Scaling good UI/UX fast
We’re currently at a pivotal moment in AI engineering, where web development plays an increasingly significant role. Shawn Wang has illustrated this evolution with his concept of the “shift right” caused by generative AI. Traditionally, AI tasks were concentrated on the data and research end (left side). Now, they’re extending towards product and user-focused applications (right side) due to the transformative impact of Transformer architectures.
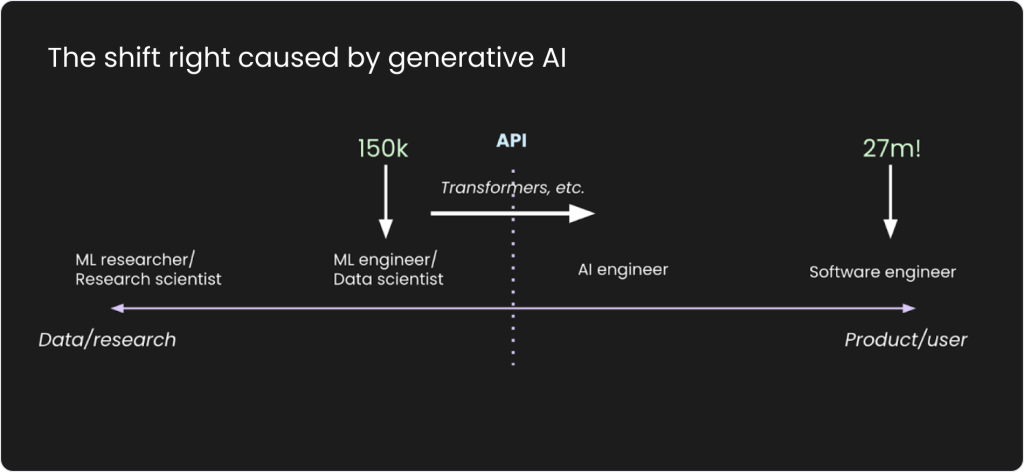
This shift allows a broader range of developers to engage with AI through APIs, leading to the emergence of AI engineers who specialize in building AI applications at the API level instead of at the model layer. With only about 150,000 machine learning engineers globally versus 27 million software developers, this convergence enables a broader range of developers to engage with AI through APIs. This cross-disciplinary integration is catalyzing the development of new tools that accelerate the creation of AI applications.
As web developers step into the new role of AI engineers, we’ve identified four best practices for building rapid UI and UX.
Tried-and-true technologies
There’s no need to try and reinvent the wheel. Focus on web standards or aligning on a stack. Maybe you want to use Python throughout the entire stack or maybe you want to stay with web standards like HTML or Javascript. Stick to established and consistent technologies.
State-driven UI and separation of concerns
Implementing a state-driven UI and maintaining a clear separation of concerns between backend and frontend logic is crucial — especially with the integration of LLMs and prompt layers. Separating backend and frontend logic prevents the intermingling of code. This will simplify debugging and maintenance, and is essential for managing the new complexities introduced by the new model layer.
Multimodal-first UX
Adopt a multimodal approach from the start. Modern web development — especially in the AI era — transcends the traditional text-based interfaces of Web 2.0 to include different inputs like images, audio, and maybe even video someday. This shift requires a fundamental change in perspective from the web development practices of the 90s and 2000s, paving the way for more dynamic and interactive experiences with web technologies.
New power tools
Finally, take advantage of the latest power tools to improve your development process. For JavaScript developers, explore tools like v0 by Vercel, which allows you to design front ends through conversation. For Python developers, the WRITER Framework is a must-try. It’s free, open source and enables rapid Python application development and AI integration — offering tight integration with various models through simple API usage.
How WRITER can help you escape AI POC purgatory
At WRITER, we’ve developed our own LLMs and RAG technology, establishing ourselves as a full-stack platform for creating everything from AI digital assistants to workflows to full applications. As the only fully integrated solution for building AI apps with faster time to value, we’ve helped customers escape AI POC purgatory. For more insights, check out our recent webinar on the topic. Learn more on how to get generative AI applications out of development and into production.
More resources

Thought leadership
– 13 min read
Why AI-native enterprise apps are the business brain of the future

Waseem AlShikh