AI in the enterprise
– 13 min read
Beyond ‘build vs. buy’: Why a unified AI platform is the only way to scale agentic AI


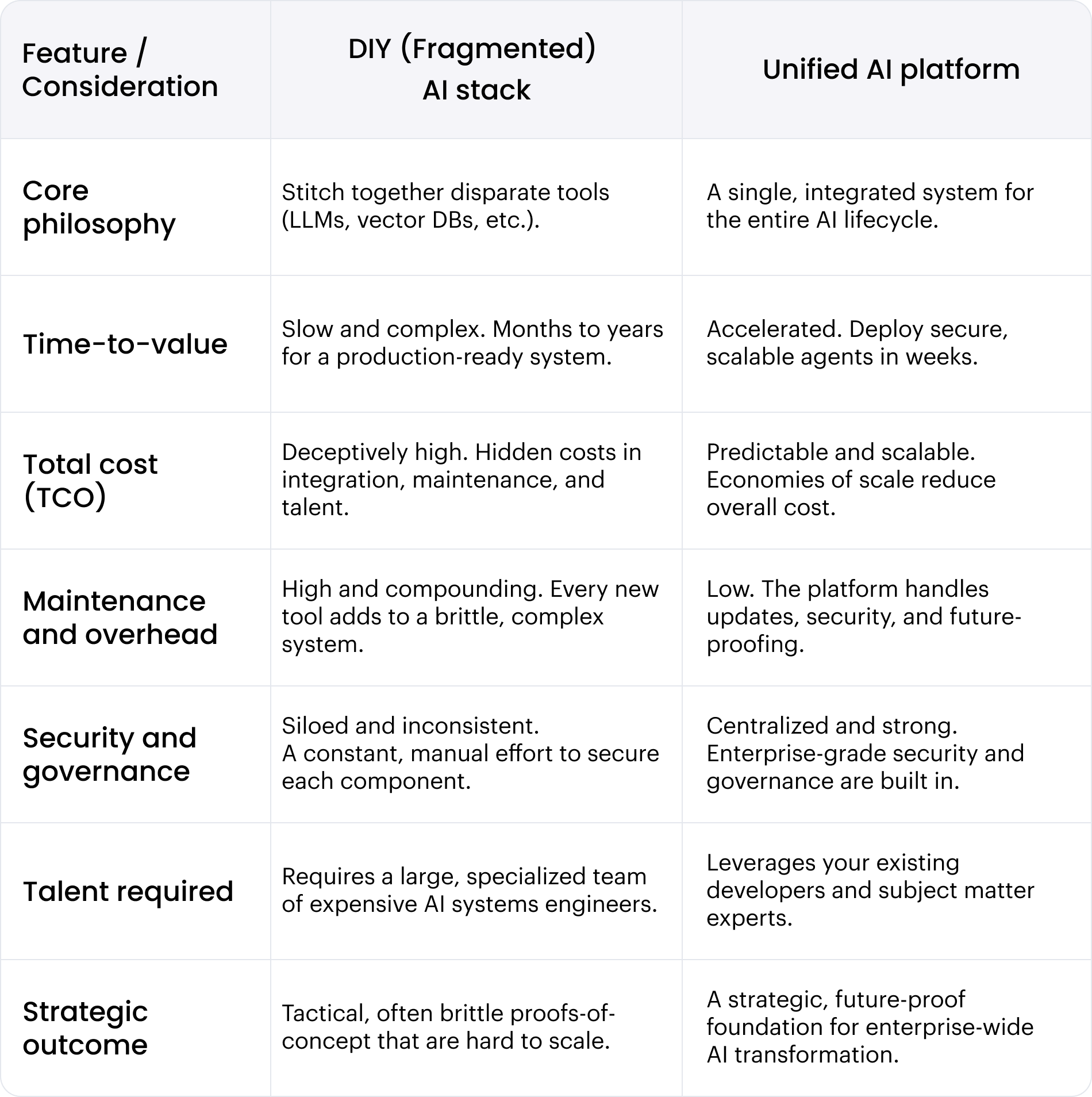
Agentic AI has shattered the old “build vs. buy” debate. The conversation is no longer about developing custom software, but about architecting autonomous systems. The allure of a DIY AI stack — stitched together from a complex set of models, vector databases, and orchestration tools — is more cost-effective or can be perfectly tailored to a company’s needs.
While a custom approach can be powerful, the reality of building an AI stack is that it’s slow, risky, and resource-intensive. The goal has shifted from simply generating content to automating outcomes. This leap from generative to agentic AI introduces a new stratosphere of systems engineering complexity.
It’s one thing to build a proof of concept that calls a model API. It’s another entirely to deploy a secure, reliable agent that can reason, self-correct, and execute multi-step work in a production environment.
What’s the real choice? A DIY AI stack vs. a unified AI platform
The debate must evolve beyond a simple “build vs. buy” calculation. The more strategic question is whether to invest in a fragmented AI stack or a unified AI platform. A DIY stack creates brittle integrations and compounding maintenance costs as technology evolves at an unprecedented pace. A platform approach is designed for economies of scale, providing an integrated, secure, and future-proof foundation for AI transformation.
Ultimately, the decision hinges on a company’s strategic readiness. The question isn’t if you can build a single agent, but if you have the deep-seated systems, talent, and processes to support an entire AI program long-term.
What are the hidden costs of a DIY AI stack?
Building an agentic AI system in-house involves more than just the typical costs for servers, databases, and storage. At its core, a DIY AI stack requires you to select, integrate, and maintain a complex set of technologies. It starts with a Large Language Model (LLM) as the reasoning engine and a Retrieval Augmented Generation (RAG) system for the knowledge base.
An LLM is the foundation — a massive model that uses machine learning to reason and generate output. The market offers many options, each with trade-offs. Skill-specific models can excel at narrow tasks like image analysis but fall short for general problem-solving. Today’s frontier models can handle diverse tasks but become cost-prohibitive to operate at an enterprise scale.
To be truly effective, an enterprise agent can’t rely solely on the public knowledge of its base LLM. It must be grounded in your internal company data. This is where RAG becomes critical, allowing an agent to access and reason over your proprietary information to provide accurate, context-aware responses. A common way to implement RAG is with vector retrieval, which combines embedding models and vector databases to convert and store your data for fast access.
However, building just this one component of your AI stack — the knowledge system — can become expensive quickly. Gartner found that extending models with data retrieval can cost between $750,000 and $1,000,000, typically requiring 2–3 dedicated engineers just for this single system, creating significant technical debt before you’ve even deployed your first agent.
Once it’s running, operational costs depend on cost-per-query, which has two main parts:
- Vector storage and querying costs: The more data you need your agent to know and the faster it needs to respond, the higher your costs for data storage and replicas.
- LLM RAG costs: RAG is expensive because every query requires you to load large chunks of retrieved documents into the LLM’s context window. With costly models like GPT-4, these token costs can skyrocket.
For example, a mid-sized enterprise processing 200,000 queries a month against a knowledge base of 100,000 pages (roughly the size of the Encyclopedia Britannica) could face costs exceeding $190,000 per month just for the RAG system to know things. It still can’t do anything..
But a knowledgeable system isn’t an agent. An agent must act.
The next, and far more complex, challenge is building the agentic layer on top of your RAG system. This involves developing the orchestration, security, and tooling that allows the agent to go beyond answering questions and start executing multi-step tasks. This could be a chat interface for employees or a backend agent that automates a complex workflow. To be effective, these agents must securely deploy within existing workflows.
The cost of building a single, custom agent is staggering. We’ve seen development costs range from $600,000 to $1,500,000 for a single agent. If you want to scale to five agents, you could be looking at a $5 million investment, not including recurring annual maintenance costs of $350,000 to $820,000 for each one.
This is where the economics of a DIY stack completely collapse. You find yourself in a cycle of rebuilding costly infrastructure for every new use case. An integrated platform, in contrast, provides the core agentic services — RAG, orchestration, security, and tool integration — out of the box. This allows you to focus on a cycle of building high-ROI agents, not on maintaining a collection of expensive, disconnected systems.

The hidden costs of a DIY AI stack
Learn more
What is the economic advantage of a unified AI platform?
Adopting a unified AI platform fundamentally changes the cost structure of your AI initiatives. Instead of the high, unpredictable capital expenditures and ongoing maintenance of a DIY stack, you move to a predictable operational model. A true platform eliminates the need to build and rebuild core agentic infrastructure — the reasoning engines, orchestration, security frameworks, and tool integrations — for every new use case.
While a platform has associated licensing costs, these are investments in a scalable foundation, not just fees for a product. These typically include:
- Annual platform access: A fee for the core, managed infrastructure.
- Onboarding and enablement: Costs to train your teams to become expert agent builders.
- Usage-based subscription: Costs tied to value, such as per agent or by query volume.
Even with these costs, the TCO is dramatically lower. Your internal resources, including valuable engineering talent, are freed from maintaining brittle infrastructure and can focus on what matters — identifying high-value business problems and rapidly deploying agents to solve them. Instead of spending millions to build a handful of siloed agents, you can invest a fraction of that to develop a whole portfolio of solutions on a common, secure architecture.
This is because a mature platform provides more than just pre-integrated services — it delivers enterprise-grade components that are beyond the scope of most in-house teams. For example, a basic DIY RAG system might use vector retrieval. In contrast, a platform like WRITER provides Knowledge Graph, a sophisticated system that understands the complex semantic relationships and hierarchies within your company data. This allows your agents to perform much deeper, more accurate analysis, moving from simple fact retrieval to genuine understanding.
Ultimately, the platform model is about risk mitigation and future-proofing. An integrated platform provides the core agentic services — RAG, orchestration, governance, security, and tool integration — out of the box. You no longer need to worry about the constant maintenance and upkeep required to keep pace with the relentless evolution of AI. The platform vendor handles the core R&D, security, and updates.
With WRITER, you also gain a strategic partner. We bring deep expertise in helping enterprises build a programmatic approach to AI, ensuring you’re not just building agents, but building the right agents that deliver measurable ROI and transform how work gets done.
Comparing the strategic value: AI stack vs. AI platform
A simple cost comparison only scratches the surface. The true difference between a DIY AI stack and a unified AI platform emerges when you evaluate the factors that determine your ability to effectively implement, govern, and scale agentic AI across the enterprise.
Time to value
When you build an agentic system in-house, the timeline is measured in months, if not years. It’s not just about piecing together services; it’s about architecting a system that can reason, plan, and act reliably. Our research with Dimensional Research found that 88% of companies building in-house solutions need six months or longer just to get a single solution operating. Scaling to a handful of agents can take years.
An AI platform compresses this timeline from years to weeks. By providing a pre-built, secure, and scalable foundation, a platform like WRITER allows you to move immediately to building and deploying a portfolio of agents. You get premium support, vetted solutions, and a partnership that helps you bypass the steep learning curve of building agentic infrastructure from the ground up.
Quality of outcomes
The goal of agentic AI is not just to produce accurate text, but to achieve reliable outcomes. Most general-purpose models lack optimization for the complex, multi-step reasoning required for enterprise tasks. This is why 61% of companies building DIY solutions report accuracy issues, and less than 10% ever progress from a proof of concept to a scaled deployment. They become trapped in “POC purgatory,” unable to bridge the gap between a simple model call and a strong, automated workflow.
An enterprise-grade AI platform focuses on business outcomes. It combines models fine-tuned for business use with a sophisticated RAG system that understands your company’s data. The WRITER platform, for instance, combines our Palmyra LLMs with our Knowledge Graph to achieve accuracy that’s nearly twice that of common alternatives, ensuring your agents don’t just respond, but execute tasks correctly and reliably.
Security and governance
In a DIY stack, security is a fragmented nightmare. Each component — the model, the vector database, the orchestration script — has its own vulnerabilities and data handling policies. Our survey found that 94% of companies consider data protection a significant concern, and for good reason. Integrating a third-party LLM often means relinquishing control of your data, as the vendor may retain it for training.
A unified AI platform provides a single, secure control plane for your entire AI program. Security is not an afterthought — it integrates into the architecture, from user access controls to data encryption and compliance with standards like SOC 2 Type II and HIPAA. This centralized governance ensures your data remains your own and that all agent activity adheres to your company’s policies.
Scaling adoption and expertise
Agentic AI represents a fundamental shift in how work gets done. Successfully scaling requires more than just building a tool — it requires building a new organizational competency. You need to identify the right use cases, train teams to think like agent builders, and manage the change process. A DIY approach leaves you to solve this complex challenge on your own.
Partnering with a platform provider like WRITER gives you access to our deep expertise in enterprise AI adoption. We help you build a programmatic approach to identifying value, training your teams, and facilitating a smooth transition, ensuring your AI program becomes a core driver of business value.
The power of an integrated agentic platform
A DIY stack is a collection of parts. An AI platform is a cohesive, integrated system where the whole is far greater than the sum of its parts. The “features” of a platform are, in fact, the core components of a strong agentic architecture — capabilities that are incredibly difficult to build, integrate, and maintain on your own. With an end-to-end platform like WRITER, everything is designed from the ground up to work together, providing a flexible and powerful foundation for your developers. Key components include:
- Dedicated AI program management: Partner with our experts to guide you from initial ideation through the entire change management process.
- Integrated user and agent management: Easily onboard users, manage permissions, and monitor agent usage from a central dashboard.
- Built-in security and privacy: Protect your data with enterprise-grade security, data encryption, and guaranteed compliance with industry standards.
- Customizable AI guardrails: Set and enforce the ethical and business rules for all your agents, ensuring they operate within your desired parameters.
- Customizable, pre-built agents: Accelerate development by adapting pre-built agents for common enterprise use cases.
- No-code and codeful AI agent development tools: WRITER offers tools for building customized AI agents, enabling both non-technical and technical teams to create, activate, and supervise AI solutions that drive business value.
- Knowledge Graph RAG: Move beyond simple RAG with a system that understands the deep context and relationships in your data, enabling more powerful reasoning.
- Fine-tuned models: Customize our Palmyra LLMs to meet your specific business needs, achieving advanced performance without the cost and complexity of training from scratch.
From cost center to growth engine: The true ROI of agentic AI
The true value of an AI initiative is measured not just in server expenses, but in the strategic outcomes it delivers. A DIY stack represents a significant investment in internal resources, and its inherent complexities often require a strong focus on maintenance, security, and technical debt. This can naturally orient the ROI conversation around operational costs and hours saved, rather than the broader scope of business value. Managing a homegrown solution means dedicating teams to patching, updating, and re-evaluating models — a critical task that requires substantial, ongoing effort.
Meaningful ROI in the age of AI, however, requires a fundamental strategic shift from task automation to outcome automation. The goal is to build, deploy, and govern a portfolio of autonomous agents that will become a true growth engine for the enterprise. This means supercharging your teams’ productivity and efficiency, but more importantly, it means creating a more agile and innovative company that can outmaneuver competitors. It means unlocking new revenue streams and reshaping your go-to-market strategy, all while safeguarding the business with enterprise-grade compliance and security.
A homegrown AI strategy, by its very nature, traps you in an operational mindset, forcing you to focus on maintenance and technical debt rather than transformation. It requires a conscious effort to evolve from an operational ROI framework to a strategic one. The rapid pace of innovation in the market means that keeping a DIY solution at the cutting edge is a significant undertaking. In this new era, ensuring your AI capabilities evolve as fast as the market is a primary strategic consideration.
A true AI platform, like WRITER, is designed to be the proven foundation for enterprise agentic AI, allowing you to focus on business outcomes from day one. Hundreds of leading companies like Uber and Qualcomm have moved beyond “POC purgatory” by using our platform to build and scale fleets of agents across their organizations. Choosing an AI platform is about more than technology. It’s about the strategic decision to invest in a scalable, secure, and ever-evolving foundation that empowers you to build the future of your business — one intelligent agent at a time.
Ready to see the end-to-end platform advantage?
Move beyond the theory. Let us show you how leading enterprises are using WRITER to deploy powerful AI agents in days, not months. We’ll walk through your specific use cases and map out a clear path to value.
More resources
Enterprise transformation
– 14 min read
How to evaluate LLM and generative AI vendors for enterprise solutions

Matt Sobel

AI in the enterprise
– 29 min read
AI ROI calculator: From generative to agentic AI success in 2025

Matthew Olson

Enterprise transformation
– 9 min read
Key findings from our 2025 enterprise AI adoption report
Writer Team